Apache Beamが多言語・多バックエンド処理系を実現する仕組み

ストリーム処理とバッチ処理を統合して扱えるプログラミングモデル(あるいはデータ処理のフロントエンド)である Apache Beam が、特にGoogle Cloud DataflowやApache Flinkからの利用を背景にシェアを伸ばしています。
Apache Beamの特色として、複数のプログラミング言語のSDKを持つこと・複数のバックエンド処理系(Flinkなどを指す)を持つことが挙げられますが、これがどう実現されているのかをまとめます。
目次
- 前提知識: Beam入門
- 前提知識: Beamでは複数種類のバックエンドが使える
- 前提知識: Beamプログラムは多言語で記述できる
- 多言語・他バックエンド対応の課題
- Apache Beamが多言語・多バックエンド処理系を実現する仕組み
前提知識: Beam入門
Exampleコードからざっくり理解
Exampleを見る前に、Beamのプログラミングをするのはどういうことかをざっくりと説明する。
Beamのプログラミング体験
Beamでプログラミングをするということは、「BeamのSDKを介して下図のようなパイプラインを構成」すること。
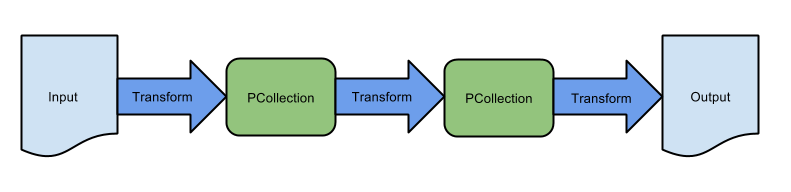
パイプラインの重要な構成要素は以下:
- PCollection: レコードが入るテーブルやキュー。データの型は単なる String であったり、リレーショナルであったり、ArrayやObjectをネストすることもできる。
- Transform: 基本的に、PCollection から PCollection への変換関数。InputをPCollectionに変換するものを特別に Read Transform , PCollectionをOutputへ変換するものを Write Transform と呼ぶ。
- Input: 任意のデータ。Read Transform が頑張ってBeam実行系が扱えるPCollectionに変換する。バッチ処理用に始めから終わりが定義されているデータでも良いし、ストリーム処理用に(概念上)無限に流れるデータでも良い。
- Output: 任意のデータ。これもbounded dataでもunbounded dataでも良い。
Beamのコードを見てみる
JavaのMinimalWordCount exampleを見る。
コメントを短縮するとこんな感じ。PCollection 出力PCollection = 入力PCollection.apply(Transform) なメソッドチェーンが続く。
1 | Pipeline p = Pipeline.create(options); // 空のパイプラインを作成 |
Beamにおけるパイプライン実行
パイプラインは、SDKを介してRunnerに渡される。パイプラインはRunnerから更にEngineに渡されてEngineが実行するのが基本である。
例えば、ストリーム処理系としてFlinkを利用し、コードはJavaで書く場合は下図のような構成になる。典型的にはRunnerはリモートサーバーで、Engineは別のリモートサーバーで稼働することになる。

主にlocal環境での動作確認やテスト用に、Direct Runnerというのも用意されている。Engineの機能も果たし、パイプライン実行までしてくれるもの。

Beamのプログラミングモデルをちゃんと理解
Beam Programming Guide を読むのが入門として一番良い。が、中々骨があるドキュメントなので、ここで「躓きやすい知識」について記載しておく。
本記事の趣旨とはずれるので、次のセクションまで読み飛ばしても良い。
Schema
6.1. What is a schema?に書かれているようなデータ型は、スキーマにできる(明示的にしなければスキーマにはならない)。- スキーマはPCollectionに紐付けられる。入力PCollectionがスキーマと紐付いている場合、PTransformとして schema transform (またの名を relational transform) が使える。
- Schema transform の出力はスキーマである(関係代数が閉包であるのと同様)ので、schema transformをつなげている部分パイプラインにおいては、スキーマ定義は最低1つで済む。
Row
- スキーマが付与されたPCollectionの1レコードのインスタンス。すなわち、あらゆるPTransformの中でrowを入力として扱えるわけではない点に注意。
Coder
- Runnerを流れるバイト列と、SDKと合わせて使うユーザー定義型(クライアントサイド)の変換を受け持つ。
- リッチなものだと、read transform が特定のフォーマットのデータ(例: JSON)をマッピングさせるのにCoder定義したり。
- もうちょっと些末なものだと、パイプラインの途中の PTransform が文字列データを入力とする時、パイプラインを流れるデータ列をUTF-8と仮定して StringUtf8Coder を使ったり。
前提知識: Beamでは複数種類のバックエンドが使える
Beam Capability Matrix に列挙されているものはBeamに認知されていて公式にRunnerが用意されている処理系。
「あなたが構成したパイプラインは DirectRunner でテストし、Google Cloud DataflowでもFlinkでも(他のでも)動かせますよ」という世界観。
豆知識だが、最も注力されているRunnerはGoogle Cloud Dataflow。次いでOSSのFlinkと言った構造。Googlerの投資をOSS陣営のFlinkが追いかけるといった様相が2016年のGoogleのブログから読み取れるが、そのパワーバランスは2022年になっても継続している模様。
前提知識: Beamプログラムは多言語で記述できる
JavaのMinimalWordCount exampleに触れたが、Java以外にもPython, Go, TypeScript用のSDKが用意されており、これらの言語でBeamパイプラインを構成することができる。
ちなみにRust SDKもGooglerから要望が高いという話がBeam Summit 2022の講演であったので、いつかサポートされるかも。
多言語・他バックエンド対応の課題
言語をまたいだUDF定義・実行が厳しい
JavaのMinimalWordCount exampleに出てきたTransformの中には、UDF (User-Defined Function) が含まれていた。
1 | .apply( |
Javaで定義されたラムダ式は、Java実装のRunnerなら実行できる(ただしSDKからRunnerにこのラムダ式を送信するための術は必要)。
しかし他の言語(e.g. JVM言語でない Go, Python, TypeScript)で実装されたRunnerでJavaのラムダ式を実行するのは困難である。
したがって、naiveに考えるとSDKを提供する言語の数だけRunner実装を作る必要がある。
EngineごとにRunnerを作る必要がある?
Runnerの役割は、各Engineに対してBeamのパイプラインをsubmitし、結果を受けることである。
各Engineのデータモデルに合わせてBeamパイプラインを変換しなければならないというのが基本路線であり、naiveに考えるとEngineの数だけRunnerを作る必要がある。
Runner実装の数 == SDK言語の数 x Engine数?
実際のところ、途中まではそのような方針だった。Flink RunnerもDataflow Runnerも、JavaにもGoにもPythonにも実装されていたりする。 (2022/08現在)
これでは言語追加もEngine追加も全くやりたくないですね…
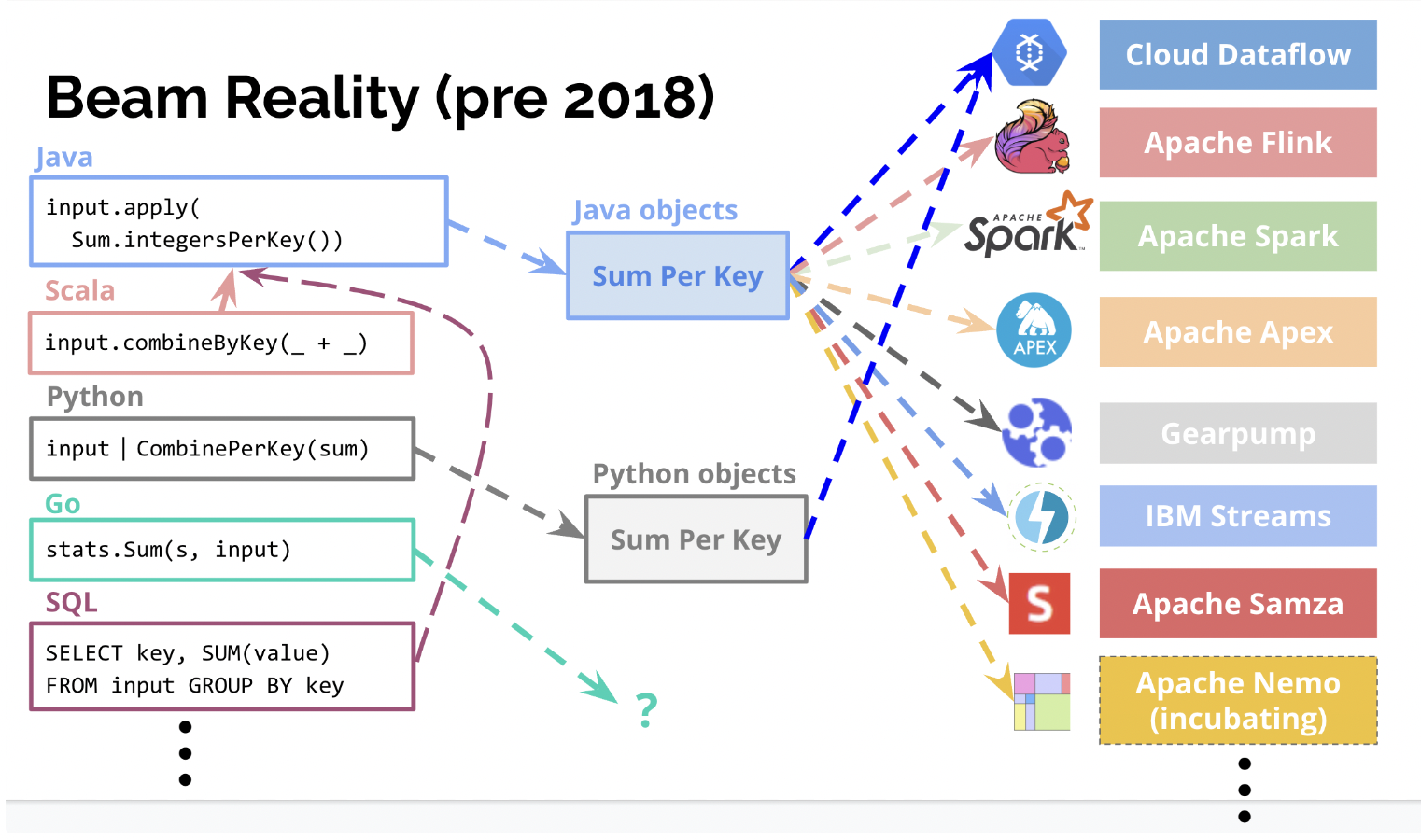
Apache Beamが多言語・多バックエンド処理系を実現する仕組み
上述の Runner実装の数 == SDK言語の数 x Engine数 問題を解決するため、2019年頃からBeamでは “Portability Framework” の導入が進められている。
Portability Frameworkは現在も開発途上であり、細かい方針転換もあったりするようなので、このドキュメントを記載する上で参照したドキュメントをまず列挙する (いずれも 2022/08/31 時点参照)。
- Runner Authoring Guide
- Fn APIの design doc
- apache/beam のJavaコード, Protobuf定義
[理想像] Portable Frameworkの仕組み
ドキュメントなどから読み解ける理想像を記載。なお、まだ全然固まっていないところもあり一部筆者の推測も含む。
Portable Runnerにより、例えば「JVMで動作するFlinkやDataflowなどのEngineを使いつつPythonで定義したパイプラインを実行」することが可能になる。
まず、UDFが登場しないパイプラインについて図解する。

これが実現できれば、Portable Runnerの実装言語は何でも良くなり、かつRunnerはPortable Runnerが1つあれば事足りるようになる。
しかし、Runner APIだけではだけではUDF実行ができない。
ProtocolBeffer(やgRPC)では「クライアント側で任意の言語で定義された関数を、別言語で実装されたサーバー側で実行する」という芸当はできないからだ。
UDFが登場するパイプラインでは下図のようになる。

新たに SDK Harness というのが登場している。この実体はDockerコンテナであり、本例では「PythonのUDFが実行できるようにPython処理系 (とBeamランタイム) が入ったDockerコンテナ」である。
Portable Runnerは、自分でもEngineでも実行できない多言語のUDF実行をSDK Harnessに委託する形である。
[2022/08] Portable Framework の現状
Portable Runner を各言語に定義する動きが見受けられる。
- Java: https://github.com/apache/beam/blob/master/runners/portability/java/src/main/java/org/apache/beam/runners/portability/PortableRunner.java
- Python: https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/portability/portable_runner.py
- TypeScript: https://github.com/apache/beam/blob/master/sdks/typescript/src/apache_beam/runners/portable_runner/runner.ts
※なぜGoに Portable Runner がないのかは未調査
SDKからRunnerへのパイプライン受け渡し部分にはRunner APIは使われていない。

また、SDK Harnessの実装はGoogle Cloud Dataflow用のものだけ進んでいるように見えて、実質SDKとRunnerの言語は合わせる必要がある状況。