二分探索木 - Rustではじめるデータ構造とアルゴリズム(第2回)
Rustの特徴のひとつは、所有権(ownership)・移動(move)・借用(borrow)の概念です。これらがコンパイル時に厳格にチェックされることにより、古くから未定義挙動でプログラマを悩ませてきたダングリングポインタなどの問題がなくなり、メモリ安全性がもたらされます。
しかし一方で、自分で多少複雑なデータ構造を定義しようとする場合にはコンパイルを通すだけでもかなりの知識・力量が要求されます。
この(不定期)連載では、 Rustではじめるデータ構造とアルゴリズム と題し、プログラミングコンテストなどでよく見かける基礎的なデータ構造とアルゴリズムを、できるだけシンプルにRustで実装していきます。 &, &mut, Box, Rc, Cell, RefCell などの使い分けや、なぜそれを使う必要があるかの解説を、実例を通して行います。
今回第2回では、 二分探索木 を取り扱います。値の大小に沿った構造を持つ二分木であり、単純なデータ構造でありながら、検索やソートなど実用性が高いです。第1回の二分木に少し制約を付け足した構造になるので、未読の方はぜひ第1回のほうからご覧ください。
連載記事一覧
- 二分木
- 二分探索木 (この記事)
- 平衡二分探索木 (未執筆)
- ヒープ (未執筆)
- 有向グラフ(ポインタ表現) (未執筆)
- 有向グラフ(行列表現) (未執筆)
- 無向グラフ(ポインタ表現) (未執筆)
- 無向グラフ(行列表現) (未執筆)


目次
二分探索木の説明
二分探索木は二分木の一種です。ただの二分木とは異なり、以下の特性を持っています。
- ノードは大小が定義できる値を持つ。
- 例: 数値, 文字列(辞書順の大小など)
- あるノードの左側の子孫ノードは、そのノードの値 以下 の値を持つ。
- あるノードの右側の子孫ノードは、そのノードの値 以上 の値を持つ。
どのノードを取っても2, 3 の性質が成立していることが二分探索木の条件です。
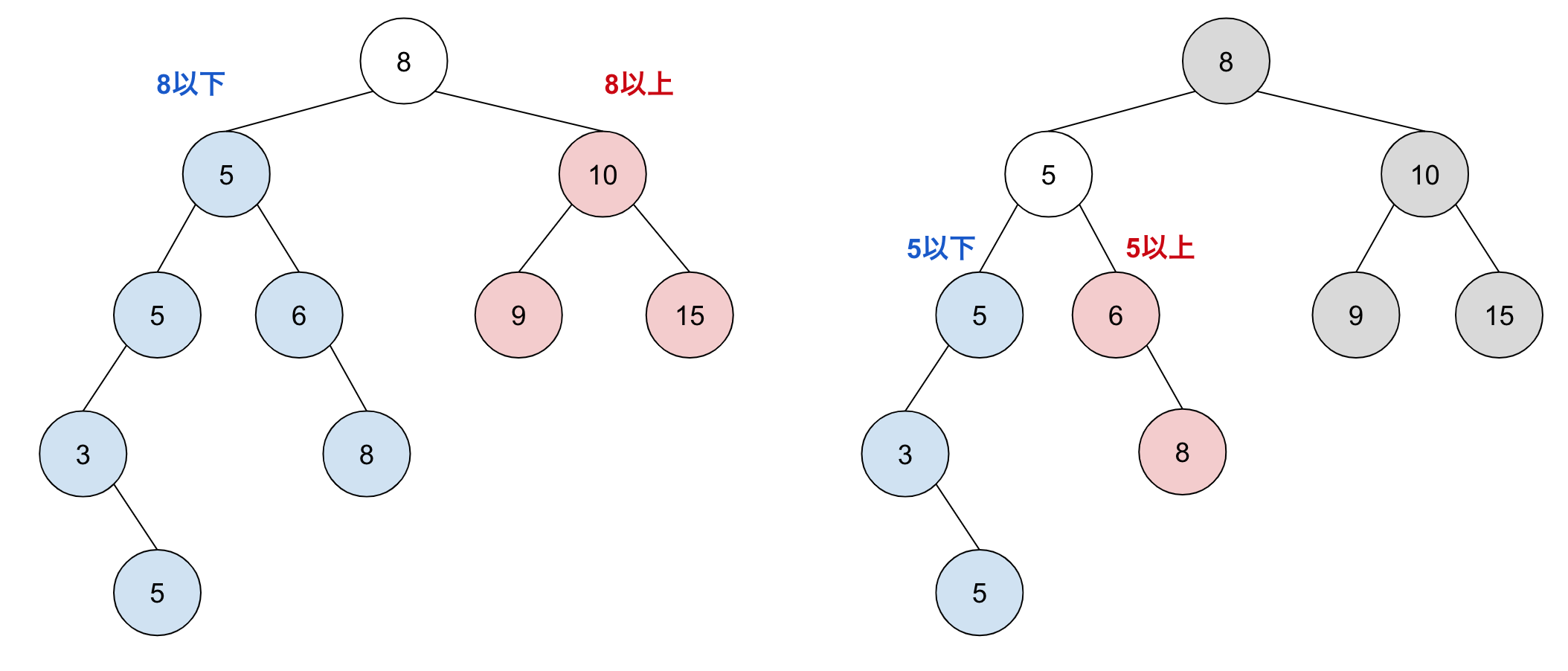
さて、二分探索木の上記の制約は、実は結構緩いです。そのため、同じ値の集合から、異なる複数種類の二分探索木を構成することができます。
上の図の2種類の二分探索木は、ともに 3, 5, 5, 5, 6, 8, 8, 9, 10, 15 の値から構成されています。では、どちらが “良い” 二分探索木でしょうか?
それを考えるためには、二分探索木の用途、すなわち関連するアルゴリズムを考える必要があります。
二分探索木のアルゴリズム: 検索
二分探索木の最も基本的な用途は 検索 です。二分 “探索” 木ですものね。
ここでいう検索とは、「パラメータとして指定した値が、二分探索木のどれかのノード値として含まれているかを判定する」操作とします。
二分探索木の要素が n 個、二分探索木の最大の深さが h だとすると、検索操作は O(h) の時間計算量で完了できます。
( O(xxx) は ビッグオー記法 です)
二分探索木の全要素数ではなく、深さの h しか計算量が掛からないため、比較的高速に検索ができるデータ構造と言えます。
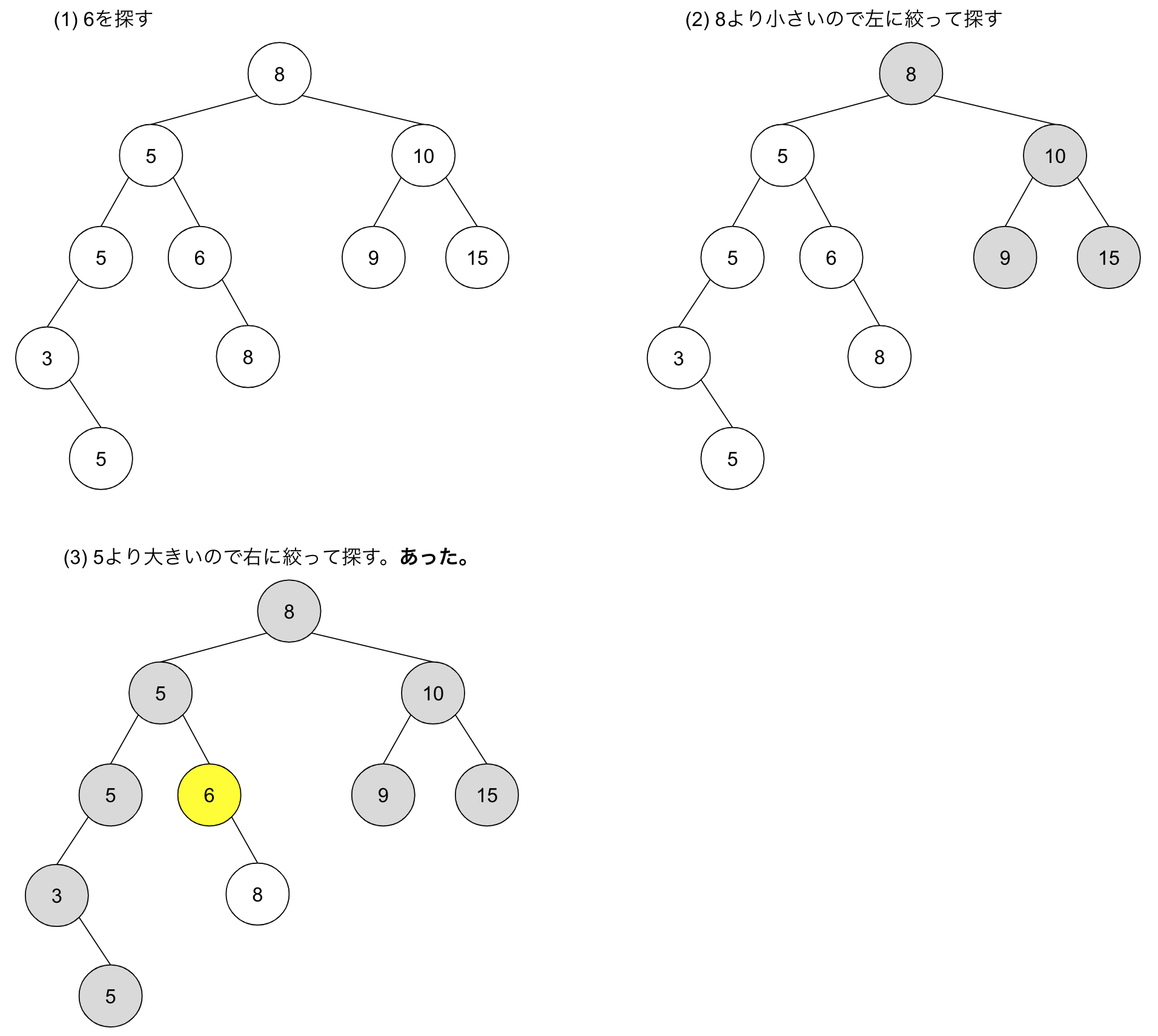
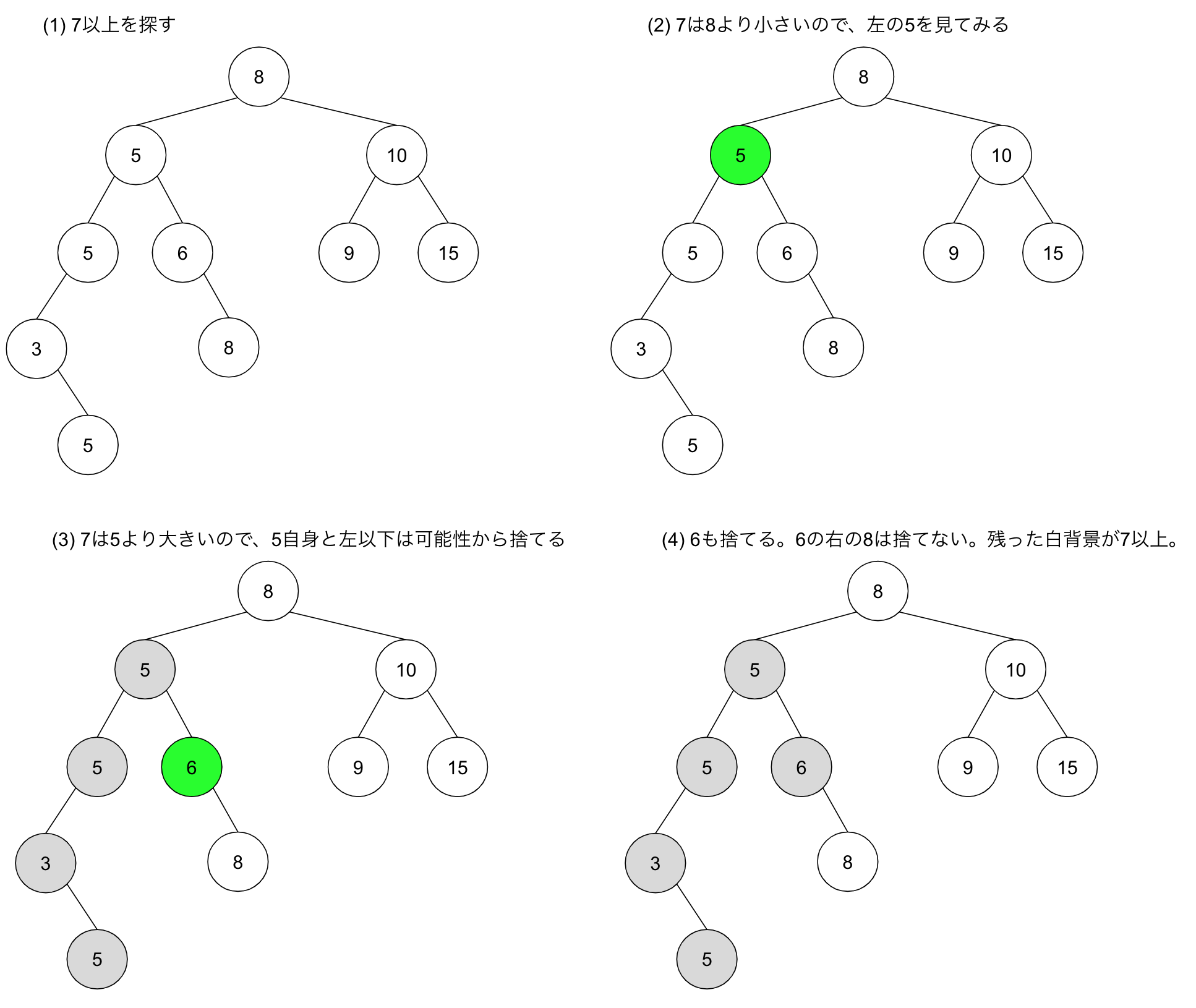
では、どのような手続きで O(h) で検索をするのでしょうか。まずは、冒頭の二分探索木から 6 を探す例を見てみます。
二分探索木は左右の子が大小関係に対応しているので、左右のどちらかの可能性を捨てながら深さ優先探索していくことが可能です。検索して見つからない例として、 11 を探す例を見てみます。
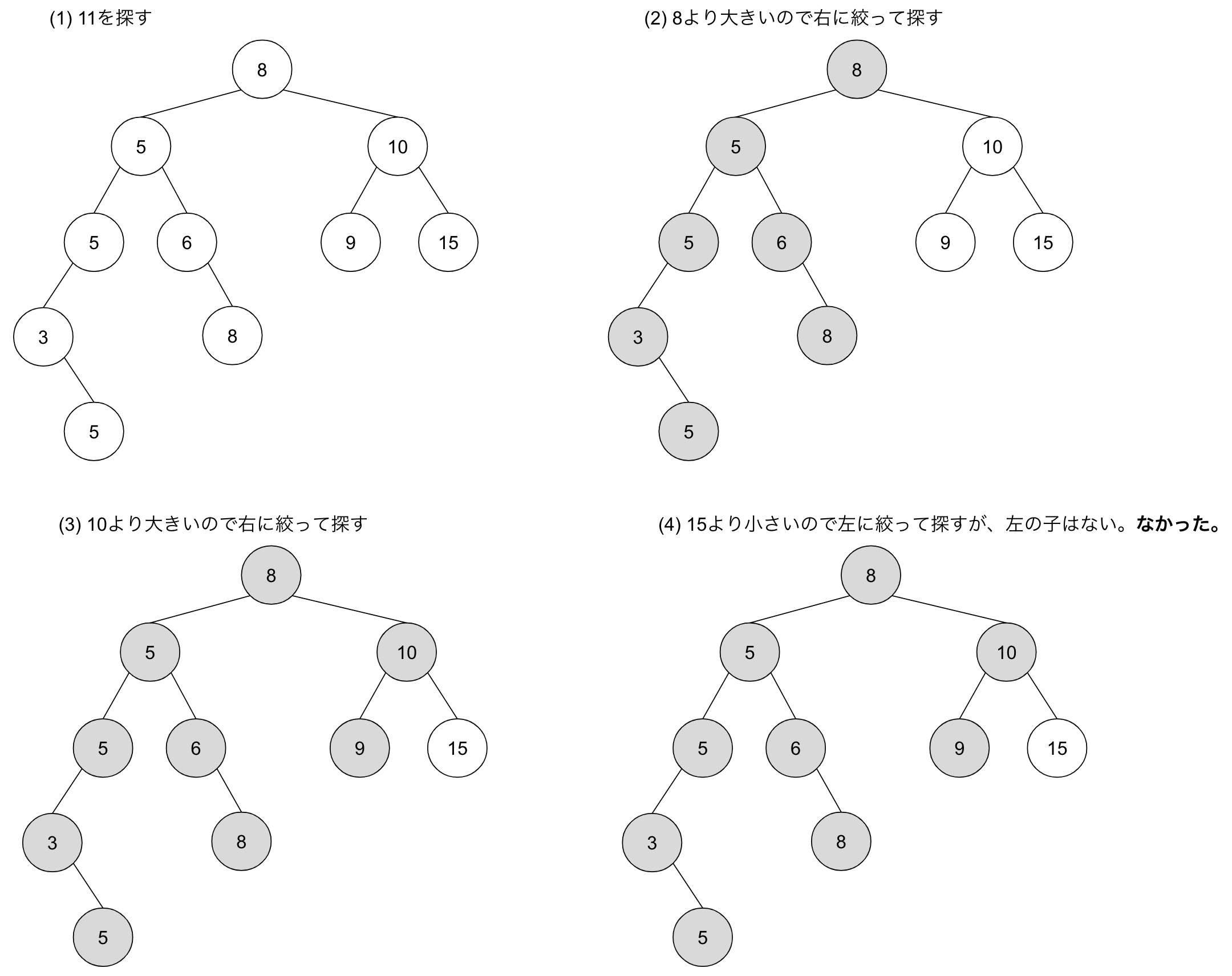
探索は必ずリーフまで続ける必要があります。 11 より大きい 15 に当たったからといって探索を停止してはいけません。先程の 6 を探す例も、 6 より小さい 5 を見つけても右への探索を続けたから 6 にたどり着きました。
以上の例からわかるように、各深さごとに1個のノードを見れば十分なので、 O(h) での探索が可能です。では先程の疑問、「 “良い” 二分探索木とはなにか」に戻りましょう。
最大の深さ h が小さければ小さいほど、「一番深いところまで見に行かないと検索に引っかからない」という最悪の場合における計算量が小さくなります。
従ってこちらの図では、最大の深さが5の左の二分探索木よりも、最大の深さが4の右の二分探索木のほうが、検索効率が良いという点で優れています。
左の二分探索木の最大の深さが大きくなってしまっているのは、バランスが取れていないからです。実は二分探索木は、どんな値の集合を持とうとも、「任意のリーフ同士の深さの差が1以内」になるように構成できます。このようにバランスが取れている(平衡している)二分探索木を 平衡二分探索木 と呼びます。上図の右は、リーフの深さが3か4なので平衡二分探索木ですね。
次回第3回で平衡二分探索木を取り上げますが、今回は平衡ではない二分探索木について説明を続けていきます。
二分探索木のアルゴリズム: 範囲検索
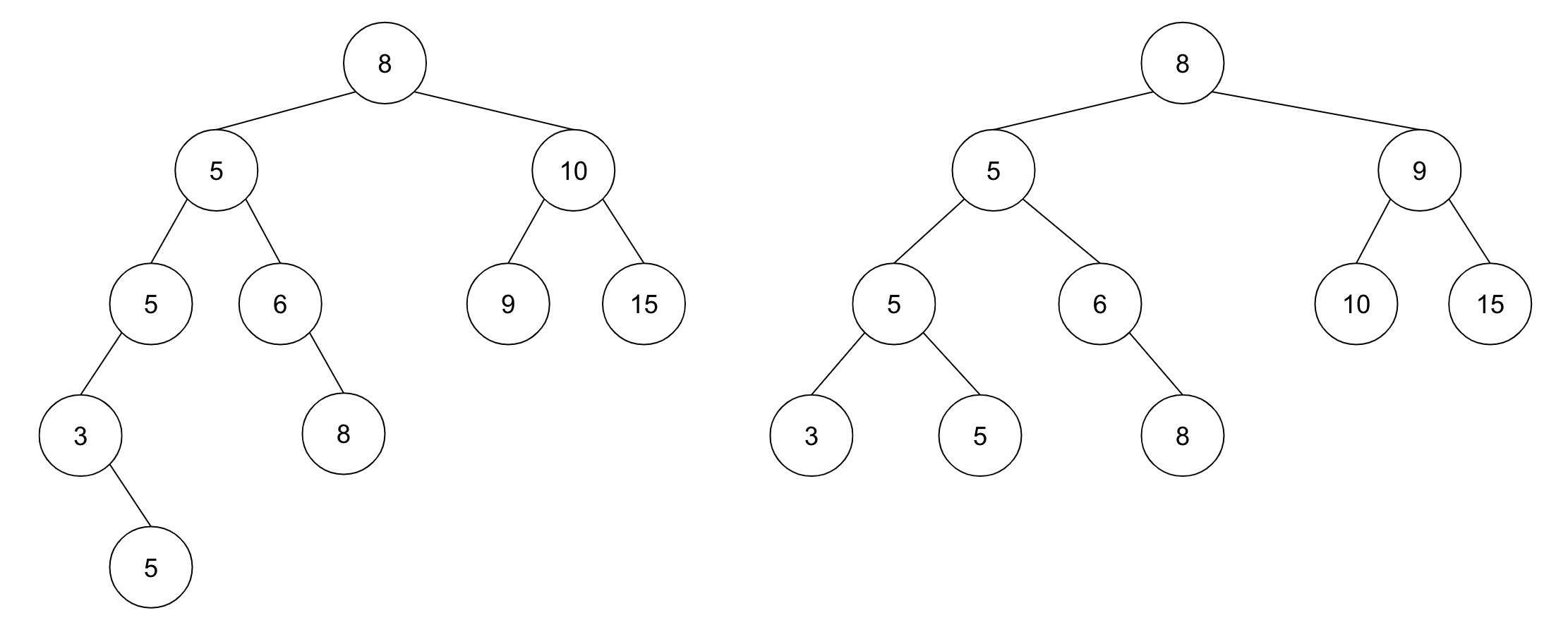
二分探索木では、値の存在の有無を調べる 一致検索 は O(h) ( h は最大の深さ) の時間計算量であることを見ました。しかし一致検索だけならハッシュテーブルなどは O(1) でできてしまいます。それでも「ハッシュテーブルがあれば二分探索木はいらない😤」とならないのは、二分探索木では 範囲検索 が効率的にできるためです。
範囲検索とは、「パラメーターとして最小値と最大値を指定する。二分探索木の値のうち、最小値と最大値の間の値をすべて返却する」操作とします。両側を挟んだ範囲検索だけでなく、最小値を無限小としたり、最大値を無限大とすることで、片側の範囲検索も同じように考えることができます。
例を見ていきます。
最小値を指定した範囲検索では、その最小値よりも更に小さいノードを見つけた瞬間に、そのノードの左のサブツリーは探索範囲から排除(枝刈り)できるのが肝です。検索範囲が広ければ、最大で二分探索木の要素数 n と同じ O(n) の計算量になってしまいますが、検索範囲が狭ければもっと小さい計算量で済みます( O(h) に近づいていく)。
二分探索木のアルゴリズム: ソート
二分探索木はソートも高速です。というより、二分探索木は値の順序性を保ちながら構築していくので、元々がソート済みというわけです。
n 個の要素の列をソートするアルゴリズムは色々ありますが、大体速いもので時間計算量 O(n * log n) 程度になります(空間計算量を多く使う基数ソートなどでは O(n) も可能ですが)。一方、要素が n 個の二分探索木からソート済みの値の列を取り出すのは、 O(n) で可能です。
計算手順は単純です。二分探索木を深さ優先探索しながら、in-place orderで値を配列に追加していけばその配列はソート済みの列になっています。in-place orderとは、「左のサブツリー、親自身、右のサブツリー」の順に処理をすることであり、一般の二分木に関する処理順序のひとつです。
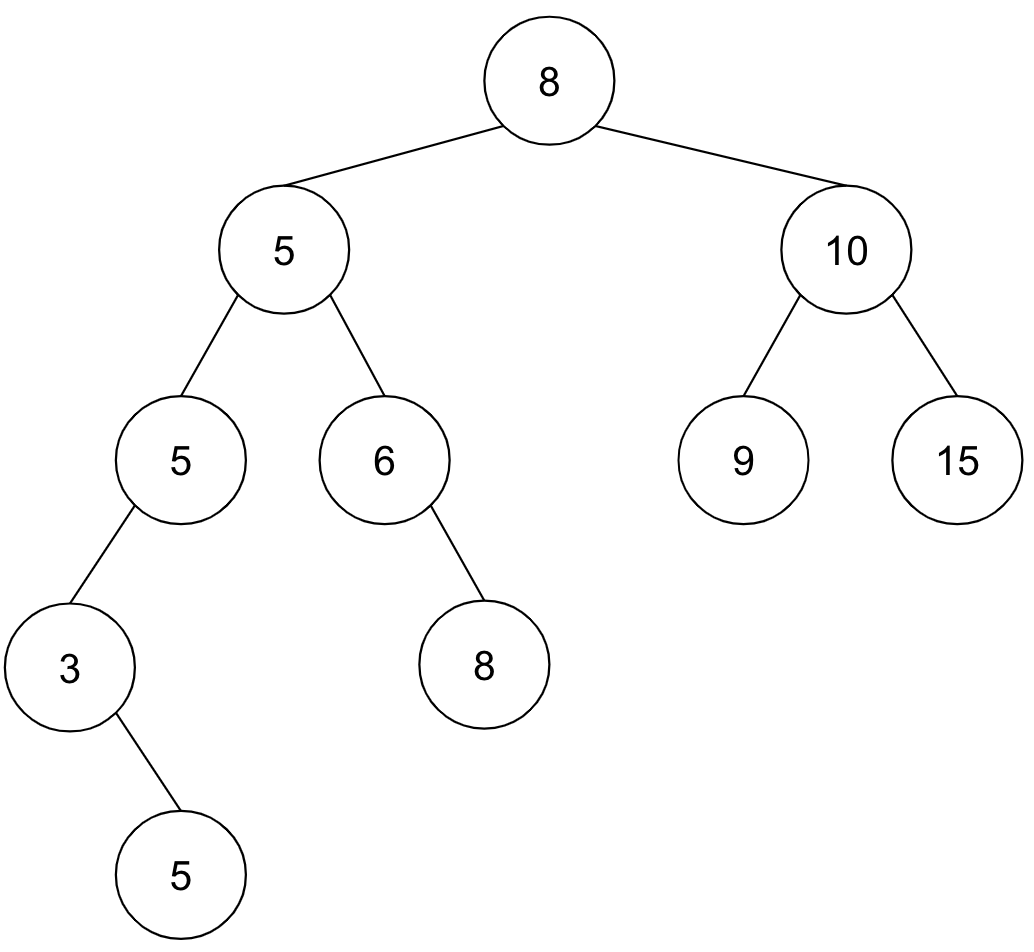
この二分探索の要素をin-place orderで出力していくと、 3, 5 (深さ5), 5 (深さ3), 5 (深さ2), 6, 8 (深さ4), 8 (深さ1), 9, 10, 15 と、ソート済みの列になりますね。
以下、in-place order に関する参考です。読み飛ばしても二分探索木の理解上問題ありません。
1 | a |
二分探索木のアルゴリズム: 値の追加
ここまでは、既に構築された二分探索木を読むアルゴリズムを見てきました。ここでは、二分探索木に値を追加していくことを考えます。
二分探索木の制約をもう一度見てみましょう。
- ノードは大小が定義できる値を持つ。
- あるノードの左側の子孫ノードは、そのノードの値 以下 の値を持つ。
- あるノードの右側の子孫ノードは、そのノードの値 以上 の値を持つ。
これを満たすような二分木は、値の集合が同じでも複数種類存在することも見てきました。
挿入方法も色々なバリエーションが考えられ、これを工夫すると深さのバランスの取れた平衡二分探索木を構成することができます。そのアルゴリズムは次回に回し、ここでは以下のようなシンプルな挿入アルゴリズムを考えます。
- 必ずリーフ要素として追加する。
- 二分探索木の制約を守るために、検索アルゴリズムと同じ考え方で、挿入すべきリーフを深さ優先探索していく。
ここまで使ってきている二分探索木に、 7 を追加することを考えます。
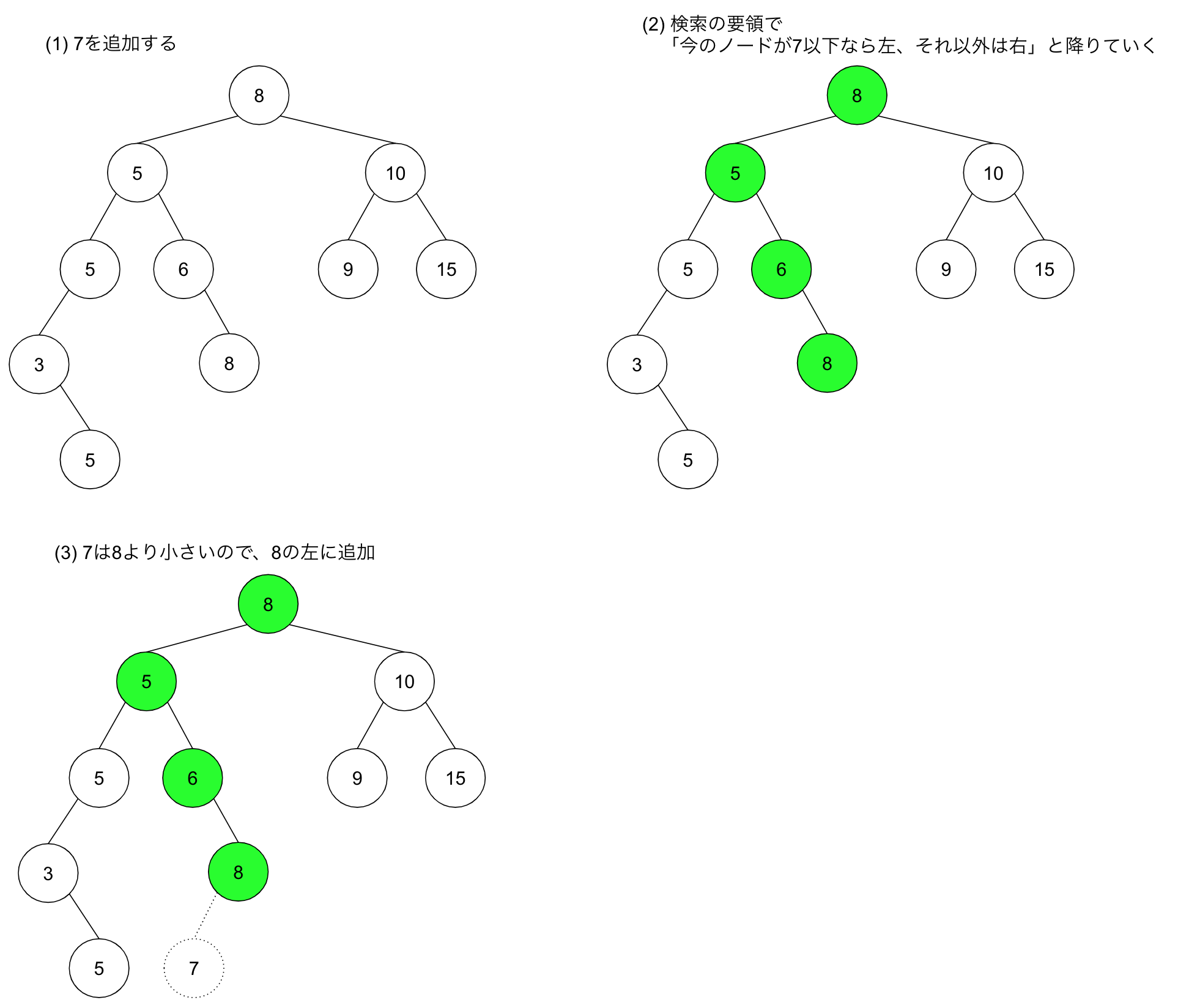
追加後の二分探索木が大小の制約を満たしていることを確認してみてください。
Rustで定義する二分探索木
データ構造とコンストラクタ
ここまでで二分探索木のデータ構造とアルゴリズムを一気に見てきました。これらをRustで実装してみましょう。まずはデータ構造から。
二分探索木のデータ構造は、二分木のデータ構造とほとんど差がありません。二分木よりも厳しい制約は「値が小さければ左、大きければ右」という値レベルのものなので、型レベルの違いではないからです。とはいえ、その値レベルの違いのルールを破らないようにするため、構築に関して縛りを入れるべきです。
第1回の二分木の構築 では、 enum BinaryTree::Node の val, left, right を直接埋めていました。これだと、 left.val > val になるような構築もできてしまい、二分探索木としては困ってしまいます。
Rustのenumは、enum自体がpublicならば全要素publicになってしまうので、structと組み合わせて「何でもできるコンストラクタ」を隠蔽し、空の二分探索木を作る new() コンストラクタを提供します。
1 | /// 二分探索木。 |
二分探索木と異なり、ノードの値が任意の型ではなく、 Ord (順序付き)であることを制約として持つ点に注意してください。
要素の追加
値を追加するメソッド add() を定義します。
1 | impl<T: Ord> BinarySearchTree<T> { |
private な再帰関数 find_nil_to_add() が登場します。これは意味合い的には add() の中の内部関数で十分なのですが、型パラメーター T を内部関数に持ってくることができないため、 BinarySearchTree のメソッドとして定義しています。find_nil_to_add() の生存期間パラメータは少々難しいポイントです。明示的に指定しなければ、 cur_node , val , 返り値の参照のすべてが同一の生存期間となります。これは制約としては少々厳しすぎます。 val はまだ二分探索木に取り込まれていない外からの値の参照なので、これの生存期間は二分探索木の生存期間と分けて定義してあげるべきでしょう。そうしなければ、
1 | { |
このコードがコンパイルエラーとなります。
使い方を示すためにも、テストコードを記載します。
1 |
|
同じ要素の集合を異なる順番で追加したとき、最終的な二分探索木が同じ構造になることも違う構造になることもあります。紙に書きながら add() のアルゴリズムをたどれば理解は難しくないはずです。
一致検索
一致検索はとても素直な再帰で書けます。
1 | impl<T: Ord> BinarySearchTree<T> { |
ソート
in-place order で Vec に値を詰めていくだけです。本当は Vec よりもイテレーターを返すほうがメモリ確保を必要なときまで遅延できるのでベターですが、ここでは二分探索木にフォーカスするために Vec を返却します。
1 | impl<T: Ord> BinarySearchTree<T> { |
範囲検索
範囲検索も、ソートと同じく in-place order で再帰処理をすれば、自然にソート済みの検索結果が得られます。「左の子以下は今見ているノードの値以下なので、探している val は絶対にない」のように枝刈りしていることに着目してください。
1 | impl<T: Ord> BinarySearchTree<T> { |
応用編: LeetCode の問題を解いてみる
説明した操作やアルゴリズムで実際の問題が解決できることを例示するために、 LeetCode から以下の問題を取り上げます。
- 938. Range Sum of BST
- 二分探索木と、最小値・最大値が与えられたとき、最小値と最大値の間のノード値の総和を回答。
これは 範囲検索 した結果の Vec を足し合わせれば一発ですね。特に新しく回答関数を書いたりする必要もありません。サンプルの入出力を確かめるテストだけ書きます。
1 |
|
終わりに
この記事ではRustで二分探索木をシンプルに定義する方法と、二分探索木の構築・追加、そして一致検索・範囲検索・ソートを紹介しました。
一致検索の説明 で指摘したように、二分探索木の強みは一致検索が O(h) (木の深さ)程度でできるだけでなく、範囲検索が O(n) (木の要素数)より小さい計算量で実現でき、もともとソート済みの構造になるので O(n) でソート済の列が得られることにあります。
ただし、ただの二分探索木の制約では、木の深さ h が最大で要素数の n になってしまいます(例: ルートに最小値、右の子ノードに次に大きい値、と小さい順に右に連ねる場合)。
次回は木の深さを小さく抑える工夫の詰まった、平衡二分探索木を紹介します。