『コンピュータの構成と設計 第5版』演習問題解答集 第4章
“パタヘネ本” でおなじみの『コンピュータの構成と設計 第5版』の解答集です。読者は書籍を保有していることを前提として解答・解説を記載します。
訂正案などありましたら本ブログ記事のリポジトリ へPull-Requestくだされば幸いです😊
この記事4章の内容は、プロセッサを実現するハードウェアユニット・パイプライン処理・命令レベル並列化など、CPUに関する中核です。
各章の解答集
- 『コンピュータの構成と設計 第5版』演習問題解答集 第1章 (執筆中)
- 『コンピュータの構成と設計 第5版』演習問題解答集 第2章
- 『コンピュータの構成と設計 第5版』演習問題解答集 第3章
- 『コンピュータの構成と設計 第5版』演習問題解答集 第4章 (この記事)
- 『コンピュータの構成と設計 第5版』演習問題解答集 第5章 (執筆中)
- 『コンピュータの構成と設計 第5版』演習問題解答集 第6章 (執筆中)
問題・解答・解説へジャンプ
4.1
次の命令を考える.
1 | 命令: AND Rd,Rs,Rt |
4.1.1
問題
図4.2において,上の命令に関して生成される制御信号の値を示せ.
解答
- RegWrite = 1
- ALU操作 = 0000
- ゼロ判定 = 0
- MemWrite = 0
- MemRead = 0
- 分岐 = 0
解説
- デスティネーションレジスタへの下記戻しがあるので、RegWriteは1。
- ALU操作の4ビット信号は、4.4節の表参照。ANDは
0000。
4.1.2
問題
この命令に関して,どのリソース(ブロック)が有用な機能を果たすか.
解答
- PC
- 命令メモリ
- 左の加算ユニット
- レジスタ
- ALU
解説
それぞれ以下の役割。
- PC
- AND命令が格納されている命令メモリ上のアドレスを指す。
- 命令メモリ
- AND命令を格納している。
- 左の加算ユニット
- AND命令の次の命令のアドレスを計算。
- レジスタ
- ソースレジスタ, ターゲットレジスタから値を読み出し、デスティネーションレジスタに値を書き戻す。
- ALU
- AND演算を実行。
4.1.3
問題
結果を出力するが,その出力がこの命令に使用されないのはどのリソース(ブロック)か.この命令に関しては結果を出力しないリソースはどれか.
解答
- 結果を出力するが,その出力がこの命令に使用されない:
- 右の加算ユニット
- データメモリ
- 結果を出力しない:
- なし
解説
「出力がない」ユニットはない。通常のデジタル回路において、各ユニットの出力は、出力端子の電圧の高低を2値で区別したものの集合であるので、出力端子の電圧が0であっても、それは「出力がない」のではなく「低電圧側の出力(通常は0)」と見なされる。
「出力を使わない」ユニットはある。使わないためには、マルチプレクサと制御信号を使う。
- 分岐の制御信号もゼロ判定の制御信号も0になるので、マルチプレクサによって右の加算ユニットの出力は選ばれない。
- データメモリは、MemRead制御信号が0であれば、マルチプレクサによって出力が無視される。
4.2
図4.2のMIPSの基本的な単一クロック・サイクル方式のプロセッサでは,一部の命令しか実装されていていない.既存の命令セット・アーキテクチャ(ISA)に新しい命令を追加したい.しかし,そうするかどうかは,必要コストと,それによって生じるプロセッサのデータパスと制御の複雑性によって決まる.次の3問では,次の命令を取り上げる.
1 | 命令: LWI Rt,Rd(Rs) |
図4.2に基づいて解答する。
4.2.1
問題
この命令のために使用できる既存のブロックがあるならば,どれか.
解答
- PC
- 命令メモリ
- 左の加算器
- レジスタ
- ALU
- データメモリ
解説
それぞれ以下の用途。
- PC
- LWI命令が格納されている命令メモリ上のアドレスを指す。
- 命令メモリ
- LWI命令を格納している。
- 左の加算ユニット
- LWI命令の次の命令のアドレスを計算。
- レジスタ
- ソースレジスタ, ターゲットレジスタから値を読み出し、デスティネーションレジスタに値を書き戻す。
- ALU
- ソースレジスタとデスティネーションレジスタの値の和を取り、それをデータメモリのアドレス値として入力。
- データメモリ
- ALUからアドレス値を入力され、そのアドレスの指す語を出力。
4.2.2
問題
この命令のために必要となる新しいブロックがあるならば,どれか.
解答
なし。
解説
4.2.3で見るように、既存のブロックを制御すれば十分。
4.2.3
問題
この命令を実装するために,制御ユニットから必要となる新しい信号があるならば,どのようなものか.
解答
なし。
解説
以下のような制御で実装可能。
- LWI命令に対応する信号を、命令メモリから制御に入力。
- 制御は、以下のように制御信号を出力。
- RegWrite = 1
- ALU操作 = 0010 (加算機能)
- ゼロ判定 = 0
- MemWrite = 0
- MemRead = 1
- 分岐 = 0
- 命令のオペランドがレジスタユニットに入力され、ソースレジスタ・デスティネーションレジスタ・ターゲットレジスタの3つが選択される。
- レジスタユニットから、ソースレジスタとデスティネーションレジスタの値が出力される。制御信号とマルチプレクサにより、ALUへの入力として、(命令の即値オペランドではなく)レジスタの値が選ばれる。
- ALUでソースレジスタとデスティネーションレジスタの値の和が計算され、出力される。
- データメモリにALUの計算結果がアドレスとして入力される。制御信号MemReadが立っているので、そのメモリの値が読まれ、デーメモリから出力される。
- レジスタユニットへのデータ入力は、制御信号とマルチプレクサにより、(ALUからの出力ではなく)データメモリからの出力が選ばれる。結果としてターゲットレジスタにデータメモリの出力が書き戻される。
4.3
プロセッサのデータパスの改善を設計者が検討するとき,意思決定の鍵となるのは通常,コストと性能のトレードオフである.次の3問では,図4.2のデータパスの改善を検討する.このデータパスの命令メモリ,加算,マルチプレクサ,ALU,レジスタ,データ・メモリ,制御ブロックのレイテンシはそれぞれ,400ps,100ps,30ps,120ps,200ps,350ps,100psとする.また,コストはそれぞれ,1000,30,10,100,200,2000,500とする.
ALUに乗算器を追加することを検討する.乗算器を追加すると,ALUのレイテンシが300ps長くなり,コストが600高くなる.結果として,実行される命令数が5%減る.MUL命令をエミュレートする必要がなくなるからである.
4.3.1
問題
この改善を行った場合と行わなかった場合の,クロック・サイクル時間はそれぞれいくつか.
解答
乗算器なし: 1430 ps
乗算器追加: 1730 ps
解説
クロックサイクル時間は、1クロックで生じるデータフローのうち、所要時間が最も大きいクリティカルパスに要する時間である。
図4.2をより抽象化しデータフローグラフにしたのが下図(配線が下手すぎる😡)

赤色のエッジがクリティカルパスである。レイテンシの総和は(最後のレジスタ書き戻しにも200psかかると考えて)、
- 乗算器なし: \(400 + 100 + 200 + 30 + \textcolor{red}{120} + 350 + 30 + 200 = 1430 \rm{[ps]}\)
- 乗算器追加: \(400 + 100 + 200 + 30 + \textcolor{red}{420} + 350 + 30 + 200 = 1730 \rm{[ps]}\)
4.3.2
問題
この改善を行うと,どれだけの速度向上が達成されるか.
解答
\(\frac{1430}{0.95 \times 1730} = 0.87 倍\)
解説
速度は低下している。
4.3.3
問題
この改善を行った場合と行わなかった場合の,コスト性能比を比較せよ.
解答
0.75
解説
- 改善前後の性能比:
- 4.3.2 の通り、0.87倍
- 改善前後のコスト比:
- コストは、4.3.1で示した図の各ノードのコストの総和(クリティカルパスは無関係)である。
- 改善前: \(30 + 30 + 10 + 1000 + 200 + 10 + \textcolor{red}{100} + 500 + 10 + 2000 = 3890\)
- 改善後: \(30 + 30 + 10 + 1000 + 200 + 10 + \textcolor{red}{700} + 500 + 10 + 2000 = 4490\)
- よってコスト比は \(\frac{4490}{3890} = 1.15\)
- 以上より、コスト性能比は \(\frac{0.87}{1.15} = 0.75\) 。悪化している。
4.4
次の3問では,プロセッサのデータパスを実装するために必要な論理ブロックが,下の表に示すとおりであるとする.
| 命令メモリ | 加算 | マルチプレクサ | ALU | レジスタ | データメモリ | 符号拡張 | 2ビット左にシフト |
|---|---|---|---|---|---|---|---|
| 200ps | 70ps | 20ps | 90ps | 90ps | 250ps | 15ps | 10ps |
4.4.1
問題
プロセッサに求められていることが命令を連続的にフェッチすることだけであるとしたら(図4.6),サイクル時間はどうなるか.
解答
200ps
解説
問題4.4は、図4.11を念頭に答えていく。
命令フェッチのみをしていくなら、1サイクルの動きは以下の通り。
- PCの値を読み出して、その値(アドレス)が指す命令語を命令メモリから読み取る。
- PCの値を読み出して、その値(アドレス)に4を加算し、結果をPCに書き戻す。
これらは、1クロックの中で同時並行で行える。したがってサイクル時間は長い方に律速され、前者の 200ps となる。
4.4.2
問題
図4.11と似ているが,無条件PC相対分岐だけを実行するプロセッサについて考える.このデータパスのサイクル時間はどうなるか.
解答
315ps
解説
1サイクルの動きは以下の通り。
- PCの値を読み出して、その値(アドレス)が指す命令語を命令メモリから読み取る。
- 命令語の下位16ビットを取り、符号拡張する。
- 符号拡張した結果を、2ビット左シフトする(命令アドレスは必ず下位2ビットが0になるようにアラインされているので)。
- PCの値を読み出して、その値(アドレス)に4を加算する。
- の出力と 3. の出力を加算する。
- マルチプレクサを通して、(4. の出力ではなく)5. の出力を採択し、PCに書き戻す。
データフローとして、 1 -> 2 -> 3 -> 5 -> 6 という依存がある(5は4にも依存する。4は1と同時に計算でき、1~3よりはずっと速い)。
これらが1サイクルになるので、サイクル時間は \(200 + 15 + 10 + 70 + 20 = 315 \rm{ps}\)
4.4.3
問題
問題4.4.2と同じ問いに答えよ.ただし,今度は,条件付きPC相対分岐だけをサポートするものとする.
解答
420ps
解説
1サイクルの動きは以下の通り。
命令フェッチ
- PCの値を読み出して、その値(アドレス)が指す命令語を命令メモリから読み取る。
条件判定
- 命令語の上位25~16ビットから、読み出しレジスタ1, 2を特定し、値を読み出す。
- ALUへの入力値として、マルチプレクサを通して、(符号拡張した命令後の下位16ビットではなく)読み出しレジスタ2の値を採択する。
- ALUで読み出しレジスタ1, 2の値の一致または不一致判定。判定結果は、右の加算器の先のマルチプレクサの制御に使われる。
条件成立時の分岐先アドレス計算
- 命令語の下位16ビットを取り、符号拡張する。
- 符号拡張した結果を、2ビット左シフトする(命令アドレスは必ず下位2ビットが0になるようにアラインされているので)。
- PCの値を読み出して、その値(アドレス)に4を加算する。
- の出力と 6. の出力を加算する。
- マルチプレクサを通して、条件判定結果に応じ、8. の出力または 7. の出力を採択し、PCに書き戻す。
クリティカルパスのサイクル時間は、 1 -> 2 -> 3 -> 4 -> 9 で、サイクル時間は \(200 + 90 + 20 + 90 + 20 = 420 \rm{ps}\)。
(1 -> 5 -> 6 -> 8 -> 9 も比較的長いが、これは 4.4.2 で求めたとおり、315ps なのでクリティカルパスではない。)
4.4.4
問題
次の3問では,データパス中の要素である「2ビット左にシフト」を取り上げる.
このリソースを必要とする命令は何か.
解答
- 無条件PC相対分岐
- 条件付きPC相対分岐
解説
これらの命令においては、命令アドレス(バイトアドレシング)を直接命令語に含む、それを2ビット右シフトした値を命令語に含む。命令長は32ビットしかないので2ビット節約するため。命令アドレスは必ず4の倍数のバイトに配置されるためこれが可能。
4.4.5
問題
クリティカル・パス上にこのリソースがある命令があるとすれば,どのような種類のものか.
解答
無条件PC相対分岐命令
解説
4.4.3で見たように、条件付きPC相対分岐においては、条件判断のほうがレイテンシが長くなる。
これはひろく一般に言えることで、条件判断にはレジスタファイルとALUが介在するが、相対アドレスを絶対アドレスにする計算には、符号拡張と左シフトしか介在せず、前者のほうがその複雑さからレイテンシが大きい場合が大半である。
4.4.6
問題
beq命令とadd命令だけをサポートしているとした場合,このリソースのレイテンシを変更すると,プロセッサのサイクル時間にどのような影響が出るかを論ぜよ.他のリソースのレイテンシは変わらないものとする.
解答
基本的にはサイクル時間は変わらない。ただし、「2ビット左にシフト」のレイテンシを極端に大きくし、beq命令において条件判断よりも、相対アドレスを絶対アドレスにする計算のほうが時間がかかるようになった場合に限り、プロセッサのサイクル時間は伸びる。
解説
特になし。
4.5
この演習問題では,パイプライン・ストールが発生せず,実行される命令の内訳は下の表に示すとおりであるとする.
| add | addi | not | beq | lw | sw |
|---|---|---|---|---|---|
| 20% | 20% | 0% | 25% | 25% | 10% |
4.5.1
問題
全サイクルのうち,データ・メモリが使用されるのはどれくらいの割合か.
解答
35%
解説
- データメモリが使用される命令は、lw, sw。割合は \(25 + 10 = 35%\)
4.5.2
問題
全サイクルのうち,符号拡張回路への入力が必要なのはどれくらいの割合か.入力が必要ないサイクルにおいて,その回路は何を行っているか.
解答
80%
入力が必要なくとも、自動的に命令語の下位16ビットが入力され、符号拡張した32ビットを出力している。
ただし、その出力はマルチプレクサで落とされる。
解説
- 符号拡張回路が使用される命令は下記:
- addi: 加算の2項目の即値16ビットを32ビットに符号拡張
- beq: 条件成立時の分岐先相対アドレス16ビットを32ビットに符号拡張
- lw: データメモリのオフセットの16ビットを32ビットに符号拡張
- sw: データメモリのオフセットの16ビットを32ビットに符号拡張
- 割合は \(20 + 25 + 25 + 10 = 80%\)
4.6
シリコン・チップを製造する際,材料(たとえば,シリコン)に欠陥があったり製造上のエラーがあったりすると,欠陥のある回路ができてしまう.非常に一般的なものは,ある配線が別の配線の信号に影響を及ぼす欠陥である.これをクロストーク欠陥と呼ぶ.クロストーク欠陥の特殊な例として,一定の論理値を有する配線(たとえば,電力供給線)に信号が接続されてしまうものがある.この場合,0謬着エラーまたは1謬着エラーが発生し,影響を受けた信号の論理値はそれぞれつねに0または1となる.以下の問題では,図4.24中のレジスタ・ファイル上のレジスタ書き込み入力のビット0を取り上げる.
膠着エラーが起き得るのが、レジスタファイルへ書き戻しされる値なのか、書き込みを受けるレジスタ(R命令ならrd, I命令ならrt)の指定子なのか問題文から判然としないが、後者であると仮定して問題を解く。
4.6.1
問題
プロセッサをテストしているとする.PC,レジスタ,データ・メモリ,命令メモリに何らかの値を設定し(値は自分で選択可能),単一の命令を実行し,その後でPC,メモリ,レジスタを読む.読んだ値をチェックして,何らかのエラーがあるかどうかを判定する.信号に0謬着エラーまたは1謬着エラーが発生しているかどうかを判定できるような,テスト(PC,メモリ,レジスタの値)を設計できるか.
解答
設計できる。
まず、レジスタファイルの各レジスタの値を0クリアする。PCを適当なアドレス値に設定し、そのアドレスの命令メモリに addi $t0, $zero, 1 の命令を格納。この命令を実行した後、 $t0 ではなく $t1 の値が1になっていれば、1膠着エラーが起きている。
同様にして、 addi $t1, $zero, 1 命令実行後に、$t0 の値が1になっていれば、0膠着エラーが起きている。
解説
特になし
4.6.2
問題
問題4.6.1と同じ問いに答えよ.ただし今度は,1謬着エラーをチェックするものとする.0謬着エラーと1謬着エラーの両方に単一のテストを適用できるか.できる場合は,その方法を説明せよ.できない場合は,その理由を説明せよ.
4.6.1で既に1膠着エラーについても問われていて、その実現方法も解答したので、前半は無視する。
解答
0謬着エラーと1謬着エラーの両方に単一のテストを適用することはできない。
0膠着エラーを見分けるには「1をセットしたのに0になった」ことを確かめる必要があり、1膠着エラーを見分けるには「0をセットしたのに0になった」ことを確かめる必要がある。単一のテストで(同一ビットに)「1をセットしたし、0をセットした」という前提を両方満たすようなことは不可能であるため。
解説
特になし。
4.6.3
問題
この信号に関してプロセッサに1謬着エラーがあるとわかっている場合でも,そのプロセッサを使用することは可能か.使用可能にするためには,通常のMIPSプロセッサ上で実行されるあらゆるプログラムを,このプロセッサで動作するように変換できなければならない.プログラムを長くしたり追加のデータを格納しても問題ないように,命令メモリにもデータ・メモリにも十分な空きスペースがあると想定してよい.ヒント:このエラーによって「妨げられる」すべての命令を,同じ機能を果たす一連の「正常に実行される」命令で置き換えられるならば,プロセッサは使用可能である.
解答
使用可能。
1膠着エラーがあった場合、R命令のrdとI命令のrtに、偶数のレジスタ指定子が使えなくなるが、それでも任意のプログラムが実現可能な(偶数レジスタ指定子の代替ができる)ことを示す。
偶数のレジスタ指定子で指定されるレジスタと、その代替方法を下記に示す。
| レジスタ | 代替方法 |
|---|---|
| $zero | 必要なタイミングで sub $t1, $t1, $t1 など実行し、値が0のレジスタを得れば良い。 |
| $v0 | $v1 を代わりに使えば良い。 |
| $a0, $a2 | 関数の引数が3個以上になるときは、関数コールの直前にcallerのスタックに引数をpushし、関数のcalleeでスタックから引数をpopすれば良い。 |
| $t0, $t2, … | $t1, $t3, … のみ使えば良い。 |
| $s0, $s2, … | $s1, $s3, … のみ使えば良い。 |
| $k0 | $k1 を代わりに使えば良い。 |
| $gp | 0x10008000 の固定値を $t9 など決まったレジスタに格納しておき、 $gp の代わりに使えば良い。 |
| $fp | “$sp + 関数フレームで伸ばしたスタックサイズ” の計算値を代わりに使えば良い。 |
解説
特になし。
4.6.4
問題
問題4.6.1と同じ問いに答えよ.ただし今度は,制御信号RegDstが0である場合には制御信号MemReadが0になるエラーが発生し,それ以外の場合にはエラーが発生しないかどうかをテストする.
「それ以外の場合」を広く捉えるとプロセッサ全体の膨大なテストが必要になるので、正常系テストは「RegDstが1である場合はMemReadの膠着エラーが発生しないこと」のみを解答すれば良いものとみなす。
解答
制御信号RegDstが0である場合には制御信号MemReadが0になるエラーが発生することのテスト:
RegDstが0なことが保証される(Don’t care ではない)のは、
lw命令の場合。lw命令ではMemReadが1になる。したがって、lwを使った以下のテストが設計できる。各種のレジスタを0クリアしておく。
命令メモリとPCを操作して、以下の命令列を実行する。
1
2
3addi $t0, $zero, 42
sw $t0, 0($gp)
lw $t1, 0($gp)$t1 の値が42ではなく0であれば、MemReadが0膠着していることが確かめられる。
RegDstが1である場合はMemReadの膠着エラーが発生しないことのテスト:
RegDstが1なことが保証されるのは、R命令の場合。R命令ではRegReadは0である。したがって、エラーの種類は「RegDstが1なのにMemReadが1に膠着」のみ。
しかしR命令では、MemtoRegが0にセットされて、メモリから読み取った値はマルチプレクサで捨てられる。
テストのために、R命令であってもわざとMemtoRegを1に膠着させ、R命令のデスティネーションレジスタに常にデータメモリからの出力値が下記戻される状況を作った上で、以下のテストを設計できる。
各種のレジスタを0クリアしておく。
データメモリの0番地を
0x1に値セットしておく。命令メモリとPCを操作して、以下の命令列を実行する。
1
add $t0, $zero, $zero
$t0 の値が1ではなく0であれば、MemReadが1膠着していないことが確かめられる。
解説
特になし。
4.6.5
問題
問題4.6.4と同じ問いに答えよ.ただし今度は,制御信号RegDstが0である場合には制御信号Jumpが0になるエラーが発生し,それ以外の場合にはエラーが発生しないかどうかをテストする.
「それ以外の場合」を広く捉えるとプロセッサ全体の膨大なテストが必要になるので、正常系テストは「RegDstが1である場合はJumpの膠着エラーが発生しないこと」のみを解答すれば良いものとみなす。
解答
制御信号RegDstが0である場合には制御信号Jumpが0になるエラーが発生することのテスト:
Jump信号の硬直エラー有無を確かめたいので、I形式の条件付き分岐命令またはJ形式の無条件分岐命令を使う必要がある。しかし、そのいずれもRegDstはDon’t careなので、テストのためにわざとRegDstを0に膠着させる必要がある。
その上で、下記のテストが設計できる。
各種のレジスタを0クリアしておく。
命令メモリとPCを操作して、以下の命令列を実行する。
1
j 0x00400000
PCの値が
0x00400000以外であれば、Jumpが0膠着していることが確かめられる。
RegDstが1である場合はJumpの膠着エラーが発生しないことのテスト:
同様に、テストのためにわざとRegDstを1に膠着させる必要がある。
その上で、下記のテストが設計できる。
各種のレジスタを0クリアしておく。
命令メモリとPCを操作して、以下の命令列を実行する。
1
j 0x00400000
PCの値が
0x00400000であれば、Jumpが1膠着していないことが確かめられる。
解説
特になし
4.7
この演習問題では,単一クロック・サイクル方式のデータパスにおいて,命令がどのように実行されるかを検討する.この問題において,あるクロック・サイクルにプロセッサがフェッチする命令を下に示す.
1 | 10101100011000100000000000010100 |
上記の命令語がフェッチされたサイクルの開始時に,データ・メモリはすべてゼロであり,プロセッサのレジスタの値は下の表に示すとおりになっているものとする.
| r0 | r1 | r2 | r3 | r4 | r5 | r6 | r8 | r12 | r31 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | -1 | 2 | -3 | -4 | 10 | 6 | 8 | 2 | -16 |
4.7.1
問題
この命令語に関して,符号拡張してジャンプするための「2ビット左シフト」ユニット(図4.24の左上)の出力を示せ.
解答
00000000 00000000 00000000 01010000
解説
図4.24 をもとに説明をする。
- 命令フェッチをしてから「2ビット左シフト」に至るまでのデータフローで、制御は発生しない。
- 命令後の15-0ビット
00000000 00010100が取り出され、符号拡張ユニットに入力される。 - 符号拡張の結果は
00000000 00000000 00000000 00010100。 - これを2ビット左シフトして、
00000000 00000000 00000000 01010000。
4.7.2
問題
この命令語に関して,ALU制御ユニットへの入力の値を示せ.
解答
101011
解説
- ALU制御ユニットには、31-26ビット目の
101011が入力される。
4.7.3
問題
この命令を実行した後の,新しいPCアドレスを示せ.その値を決定する経路を強調して示せ.
解答
PC + 4
値を決定する経路は、数の緑色の線で強調した。PCアドレス以外にも、主要なデータフローを図中に示している。
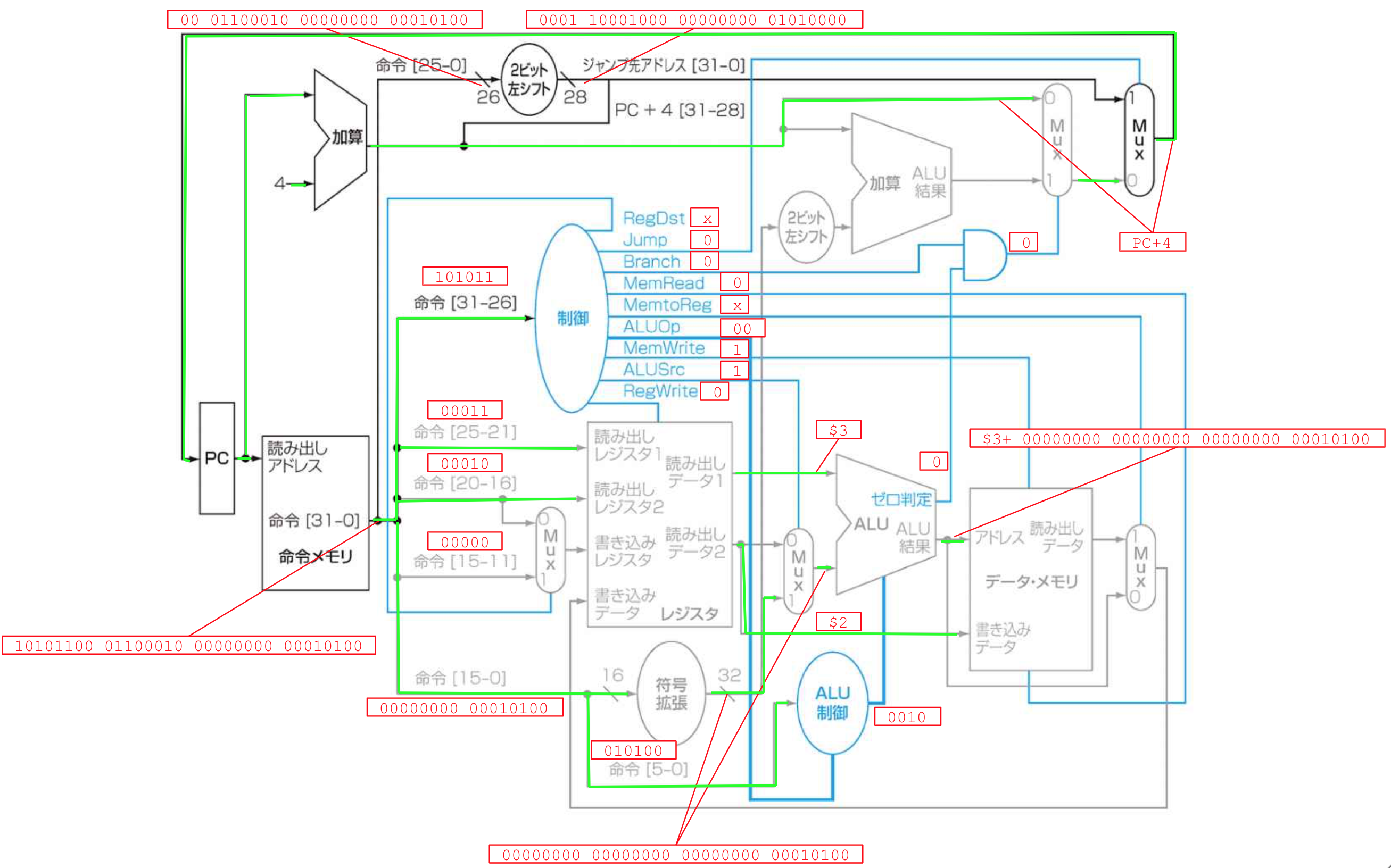
解説
opcodeを見て sw と “解釈” しないでも、機械的に sw の満たすべきデータフローになっていることに注目。
緑色になっていない配線は、将来的にどこかのマルチプレクサ、またはRegWrite=0によって落とされるデータフローである。
4.7.4
問題
上記の命令を実行したときの,各マルチプレクサの出力データと,レジスタの値をそれぞれ示せ.
解答
- 上部左のマルチプレクサ出力: PC + 4
- 上部右のマルチプレクサ出力: PC + 4
- 下部左のマルチプレクサ出力: 不明(RegDstがDon’t careであるため)
- 下部中央のマルチプレクサ出力:
00000000 00000000 00000000 00010100 - 下部右のマルチプレクサ出力: 不明(RegDstがDon’t careであるため) (MemtoRegがDon’t careであるため)
レジスタの値の書き換えは発生しないので、元のまま。
解説
4.7.3の図解通り。
4.7.5
問題
ALUおよび2つの加算ユニットの入力データ値を示せ.
解答
- ALU: レジスタ
$3の値-3と、即値00000000 00000000 00000000 00010100 - 上部左の加算ユニット: PCの値と、即値4
- 上部右の加算ユニット: PC+4と、
00000000 00000000 00000000 01010000
解説
4.7.3の図解通り。
4.7.6
問題
「レジスタ」ユニットのすべての入力値を示せ.
解答
- 読み出しレジスタ1:
00011 - 読み出しレジスタ2:
00010 - 書き込みレジスタ: 不明 (RegDstがDon’t careであるため)
- 書き込みデータ: 不明 (MemtoRegがDon’t careであるため)
解説
4.7.3の図解通り。
4.8
この演習問題では,パイプラインがプロセッサのクロック・サイクル時間にどのように影響するかを検討する.次の3問では,データパスの各ステージのレイテンシは,下の表に示すとおりであると想定する.
| IF | ID | EX | MEM | WB |
|---|---|---|---|---|
| 250ps | 350ps | 150ps | 300ps | 200ps |
また,プロセッサによって実行される命令の内訳が,下の表に示すとおりであると想定する.
| ALU | beq | lw | sw |
|---|---|---|---|
| 45% | 20% | 20% | 15% |
4.8.1
問題
パイプライン方式のプロセッサとパイプライン方式でないプロセッサの,クロック・サイクル時間をそれぞれ示せ.
解答
- パイプライン方式: 350ps
- パイプライン方式でない: 1250ps
解説
パイプライン方式でなければ、IF~WBの全ステージを1クロックで処理するので、クロックサイクル時間は全ステージのレイテンシの総和になる。
パイプライン方式では、1ステージを1クロックで処理するが、同一クロックで複数種類のステージが実行される都合上、最もレイテンシの大きいステージが律速となりクロックサイクル時間が決まる。
4.8.2
問題
パイプライン方式のプロセッサおよびパイプライン方式でないプロセッサにおける,lw命令の合計レイテンシをそれぞれ示せ.
解答
- パイプライン方式: 1750ps
- パイプライン方式でない: 1250ps
解説
パイプライン方式でなければ、4.8.1で算出したクロックサイクル時間がかかる。
パイプライン方式では、全5ステージがそれぞれ350psのクロックサイクル時間なので、5ステージ(5クロック)の分時間が命令のレイテンシとしてかかる。
4.8.3
問題
パイプライン方式のデータパスの1つのステージを2つの新しいステージに分割でき,新しいステージのレイテンシは元のステージの半分になるとする.どのステージを分割するのがよいか.また,ステージ分割後の,プロセッサの新しいクロック・サイクル時間はどうなるか.
解答
IDステージを分割すると良い。分割後は律速のステージはMEMの300psになるので、これが新しいクロックサイクル時間になる。
解説
ロードバランシングの観点から、ボトルネックになっているステージを分割するべき。
4.8.4
問題
ストールもハザードも発生しないとするならば,データ・メモリの利用率(使用されたサイクルの割合)はどれほどか.
解答
35%
解説
命令数が十分に多く、各クロックで5ステージ分の実行ができていると仮定すると、任意のクロックで全ステージの実行が行われる余地がある。
ここで “余地がある” と述べたのは、必ずしもすべての命令でMEM, WBステージを実行するとは限らないため(実行しない場合は単にそのステージで待ちが発生する)。
データメモリを利用するMEMステージを利用する命令は、本問においては lw と sw 。これらの命令は全体の35%を占める。
以上より、データメモリの利用率は35%。
4.8.5
問題
ストールもハザードも発生しないとするならば,レジスタ・ユニットの書き込みレジスタ・ポートの利用率はどれほどか.
解答
65%
解説
4.8.4と同様の論旨。
レジスタユニットの書き込みレジスタポートを利用する命令は、本文においてはALU, lw であり、全体の65%を占める。
4.8.6
問題
単一クロック・サイクル型の構成方式の代わりに,マルチサイクル型の構成方式を採用することができる.マルチサイクル方式では,各命令は複数のサイクルをとり,ある命令が他の命令より早く終わることがある.この構成方式では,命令は実際に必要なステージだけを通過する(たとえばストア命令は,WBステージを必要としないので,4サイクルで終了する).単一クロック・サイクル,マルチサイクル,パイプラインのそれぞれの構成方式のクロック・サイクル時間および実行時間を比較せよ.
解答
実行時間は、与えられた命令の出現頻度のもと、100命令を実行した場合の実行時間とする。
単一クロックサイクル:
- クロックサイクル時間: 1250ps
- 実行時間: 125us
マルチサイクル:
- クロックサイクル時間: 350ps
- 実行時間: 140us
パイプライン:
- クロックサイクル時間: 350ps
- 実行時間: 35us
解説
単一クロックサイクルとパイプラインのクロックサイクル時間は、4.8.1で回答したとおり。
マルチサイクル方式でのクロックサイクル時間を考える。同時に1命令中の1ステージしか実行しないため、ステージごとの「変動クロックサイクル時間」のような方式を論理的には考えられそうだが、さすがにクロックサイクル時間は一定にしないとハードウェア製造の観点で現実的ではないと考える。とすると、結局パイプライン方式と同様に、最も遅いステージに律速されるので、350psがマルチサイクル方式でのクロックサイクル時間。
あとは、ALU命令が45回, beq が20回, lw が20回, sw が15回 実行されることから、実行時間は以下のようになる。
単一クロックサイクル:
\[
1250 \rm{[ps]} \times 100 \rm{命令} = 125,000 \rm{[ps]}
\]
パイプライン(14個目, 97100個目の命令では命令数が足りずに5並列にならないが、その影響は無視する):
\[
350 \rm{[ps]} \times 5 \rm{[stages]} \times 100 \rm{命令} \times \frac{1}{5 \rm{並列}}= 35,000 \rm{[ps]}
\]
マルチサイクル:
\[
\begin{eqnarray}
&& (350 \rm{[ps]} \times 4 \rm{[stages]} \times 45 \rm{命令}) \\
&+& (350 \rm{[ps]} \times 3 \rm{[stages]} \times 20 \rm{命令}) \\
&+& (350 \rm{[ps]} \times 5 \rm{[stages]} \times 20 \rm{命令}) \\
&+& (350 \rm{[ps]} \times 4 \rm{[stages]} \times 15 \rm{命令}) \\
&=& 140,000 \rm{[ps]}
\end{eqnarray}
\]
マルチサイクル方式が速くなるための条件は、
- 各ステージのレイテンシに差が少なく
- 特定のステージをスキップできる命令が多い
ことと考えられる。
4.9
この演習問題では,4.5節で説明した基本的な5ステージのパイプラインにおいて,データの依存関係が実行にどのような影響を及ぼすかを検討する.この問題では,下に示す命令列を取り上げる.
1 | or r1,r2,r3 |
また,クロック・サイクル時間が下の表に示すとおりであるとする.
| フォワーディングなし | 全面的にフォワーディングあり | ALU同士の間のフォワーディングのみあり |
|---|---|---|
| 250ps | 300ps | 290ps |
4.9.1
問題
依存関係とそのタイプを示せ.
解答
- 命令1と命令2の
r1: RAW - 命令2と命令1の
r2: WAR - 命令1と命令3の
r1: RAW, WAR - 命令2と命令3の
r1: WAR - 命令2と命令3の
r2: RAW - 命令3の中の
r1: WAR
解説
書籍の中で記載は見られなかったが、データ依存の種類としてRAW (Read After Write) とWAR (Write After Read) を持ち出した。
4.9.2
問題
このパイプライン方式のプロセッサでは,フォワーディングは行われないとする.ハザードを指摘し,それを回避するためにnop命令を追加せよ.
解答
- 1つ目と2つ目の命令において、r1に関するデータハザードがある。
- 2つ目と3つ目の命令において、r2に関するデータハザードがある。
以下のようにnopを挟めば良い。
1 | or r1,r2,r3 |
解説
まずはデータハザードを気にせずにパイプライン図を描く。

フォワーディングがない場合、以下のハザードがある。
- 2つ目の命令のIDはr1を必要とするが、それが1つ目の命令からWBされるまでには、もう2クロック必要。
- 3つ目の命令のIDはr1を必要とするが、それが2つ目の命令からWBされるまでには、もう2クロック必要。
よって、nopは2箇所に挟む必要がある。

同一クロックにおいて、2つ前の命令のWB結果をID入力として使える点に注意(クロック前半で書き込みが、後半で読み出しが行われる)。
4.9.3
問題
このプロセッサでは,フォワーディングが全面的に行われるとする.ハザードを指摘し,それを回避するためにnop命令を追加せよ.
解答
ハザードはなく、nopは不要。
解説
まずはデータハザードを気にせずにパイプライン図を描く。

前の命令のEXからのフォワーディングが次の命令のEXに間に合っているので、nopは不要。
4.9.4
問題
フォワーディングなしの場合と,全面的にフォワーディングありの場合の,上記の命令列の合計実行時間を示せ.フォワーディングなしのパイプラインに全面的なフォワーディングを追加した場合に,速度はどれだけ向上するか.
解答
- フォワーディングなし: 11クロック
- 全面的にフォワーディングあり: 7クロック
速度向上は \(\frac{11 \times 250 \rm{ps}}{7 \times 300 \rm{ps}} = 1.30\)
解説
特になし。
4.9.5
問題
ALU同士の間のフォワーディングのみある(MEMステージからEXステージへのフォワーディングはない)場合に,ハザードを回避するためにこのコードにnop命令を追加せよ.
解答
1 | or r1,r2,r3 |
解説
まずはデータハザードを気にせずにパイプライン図を描く。

「3つ目の命令は、1つ目の命令のr1をWBまで待つ必要がある」というハザードがある。これを解消するためにnopを挟む。

1つ目の命令のWBステージで書き戻された r1 は、同一クロックで3つ目の命令のIDステージで読み出せる点に注意(レジスタファイルは、クロック前半で書き戻しが、クロック後半で読み出しが行われる)。
新たに、「3つ目のorは、2つ目のorのr2をWBまで待つ必要がある」というハザードが発生。nopをもう一つ挟んで完成。

4.9.6
問題
ALU同士の間のフォワーディングのみある場合の,上記の命令列の合計実行時間を示せ.フォワーディングなしのパイプラインに比べて,どれだけ速度が向上するか.
解答
- フォーワーディングなし: 11クロック
- ALU同士の間のフォワーディングのみあり: 9クロック
速度向上は \(\frac{11 \times 250 \rm{ps}}{9 \times 290 \rm{ps}} = 1.05\)
解説
特になし。
4.10
この演習問題では,リソース・ハザード,制御ハザード,命令セット・アーキテクチャ(ISA)の設計が,パイプライン方式のプロセッサの稼働にどのような影響を及ぼすかを検討する.この問題では,下に示すMIPSの命令列を取り上げる.
1 | sw r16,12(r6) |
パイプラインの各ステージのレイテンシは,下に示すとおりであるとする.
| IF | ID | EX | MEM | WB |
|---|---|---|---|---|
| 200ps | 120ps | 150ps | 190ps | 100ps |
各小問の題意がとても曖昧なので、問題文の下部に太字で前提を追加する。
4.10.1
問題
この演習問題では,すべての分岐は完全に予測され(したがって,制御ハザードはいっさい発生しない),遅延スロットは使用されないとする.メモリが1つしかない(命令用とデータ用を共用)ならば,他の命令がデータにアクセスするのと同じサイクルに命令をフェッチする必要があるたびに,構造ハザードが発生する.処理が正しく進むためには,このハザードを解決する際は常に,データにアクセスする命令を優先しなければならない.メモリが1つしかない5ステージのパイプラインの場合,この命令列の合計実行時間はどれほどになるか.前に見たように,データ・ハザードはコードにnopを追加することで回避できた.構造ハザードにも同じ方法を適用できるか.その理由はなぜか.
解答
合計実行時間: 2400ps
nop追加ではメモリに関する構造ハザードは回避できない。nopを挟んだとしても、それをIFするときには前の命令のMEMステージと重なっているので、nopを読むことができないため。
解説
まずはデータハザード・構造ハザードを気にせずにパイプライン図を描く。

この図から、データハザードはないことが確認できる。
命令メモリとデータメモリに同一クロックで同時アクセスできればこのパイプラインは問題なく処理できるが、本問の設定に従いデータアクセスを命令フェッチよりも優先する必要がある場合を考える。
このとき、 sw のMEMステージが add のIFステージと同一クロックの実行になっているので、 add 命令の実行開始は遅らせる必要がある。1クロック遅らせただけでは lw のMEMステージと同一クロックになってしまう。2クロック遅らせれば beq のMEMステージと同一クロックだが、 beq はデータメモリにアクセスしないため、これは許容される。
同様に slt のIFも他のデータメモリアクセスと重ならないようにし、下図を得る。

これより、実行に要するクロック数は11クロックである。クロックサイクル時間は最も遅いIFステージに律速され、200ps。したがって合計実行時間は \(200 \rm{ps} \times 11 \rm{clk} = 2200 \rm{ps}\) 。
4.10.2
問題
この演習問題では,すべての分岐は完全に予測され(したがって,制御ハザードはいっさい発生しない),遅延スロットは使用されないとする.ロード/ストア命令において,アドレスをレジスタに直に指定する(オフセットを使用しない)ように変更できるならば,これらの命令でALUを使用する必要はなくなる.そうすれば,MEMステージとEXステージを重ねられるので,パイプラインの長さは4ステージに短縮される.このような命令セット・アーキテクチャの変更に対応するように,上の命令列を修正せよ.ただし,この変更はクロック・サイクル時間に影響しないものとする.上の命令列の実行速度はどれだけ向上するか.
4.10.1と異なり、同一クロックでIFステージとMEMステージが実行できるものと考える。また、4.10全体でデータハザードは考慮しないので、フォワーディングは利用できるものと考える。比較対象は、4.10.1から構造ハザードを取り除いたものとする。
解答
修正した命令列:
1 | addi r6,r6,12 |
実行速度向上: 0.9
解説
sw, lw で即値オフセットが使えなくなったので、 addi 命令を追加する必要がある。新しい命令列は以下。
1 | addi r6,r6,12 |
まずはデータハザードを気にせずにパイプライン図を描く。

lw, sw 命令ではオフセット計算がなくなったのでEXステージがなくなり、 beq, add, slt 命令ではデータメモリアクセスをしないのでMEMステージがなくなった。
フォワーディングがあるので、データハザードは発生しないことに注意。
この問題においては同一クロックのIFとMEMステージでの構造ハザードも考えない。
したがって図に示したパイプラインはこのまま実行することができ、要クロック数は10。
比較対象は、4.10.1の解説の最初に描いた図(ただし構造ハザードは無視できる)のとおりに実行でき、要クロック数は9。
以上より、速度向上は \(\frac{9}{10} = 0.9\) 。 addi 命令を追加した分だけ速度が落ちている。
4.10.3
問題
分岐の際にはパイプラインにストールを挿入し,遅延スロットはないものとする.分岐の判定がIDステージでなされるようになったならば,分岐の判定がEXステージでなされる通常の命令と比べて,どれだけ速度が向上するか.
4.10.2と同様、構造ハザードはなく、フォワーディングが利用でき、MEMステージとEXステージは重ねられるものとする。
解答
1.09
解説
4.10.2では、100%の精度の分岐予測ができると想定していた。4.10.2の解説の図を元に、 “EXステージで分岐先が次の add 命令になることが判明するケース” と、 “IDステージで分岐先が次の add 命令になることが判明するケース” の図をそれぞれ記載する。
EXステージで分岐先が次の add 命令になることが判明するケース:

IDステージで分岐先が次の add 命令になることが判明するケース:

所要クロック数はそれぞれ12クロック, 11クロック。速度向上は \(\frac{12}{11} = 1.09\) 。
4.10.4
問題
上のパイプライン・ステージのレイテンシを用いて,問題4.10.2と同様に速度向上の度合いを計算せよ.ただし今度は,クロック・サイクル時間の変更(の可能性)を考慮に入れること.EXステージとMEMステージが単一のステージに統合されると,その処理の大部分を並列に進められる.その結果,統合されたEX/MEMステージのレイテンシは,元の2つのステージのレイテンシの大きい方と,並列には進められない処理のために必要な20psとの和になる.
速度向上の比較対象は、構造ハザードがなく、EX/MEMステージが統合されておらず(したがってロード・ストア命令のオフセット計算に追加の addi が不要な)、分岐先の確定はEXステージで行われるパイプラインとする。
解答
1.16
解説
- 統合されたEX/MEMステージのレイテンシは、 \(\rm{max}(150\rm{ps}, 190\rm{ps}) + 20\rm{ps} = 210\rm{ps}\) 。これは他のどのステージのレイテンシよりも多きいので、クロックサイクル時間は210psになる。
- したがって、4.10.3の「IDステージで分岐先が次の
add命令になることが判明するケース」における実行時間は、 \(9\rm{clk} \times 210\rm{ps} = 1890\rm{ps}\) 。 - 比較対象のパイプラインにおける所要クロック数は、4.10.1の最初の図に示したものと比べて
add命令の開始が2クロック遅れる(直前のbeqの不成立がEXフェーズまでわからないため)ので、11クロック。クロックサイクル時間は実行時間は律速IFステージの200psになるので、 \(11\rm{clk} \times 200\rm{ps} = 2200\rm{ps}\) - 以上より、速度向上は \(\frac{2200\rm{ps}}{1890\rm{ps}} = 1.16\) 。
- 速度向上へ寄与した要因:
- EX/MEMステージの統合
- 分岐の確定がEXでなくIDステージで行われる
- 速度低下へ寄与した要因:
- オフセット即値の代替としての
addi命令の追加 - クロックサイクル時間の増加
- オフセット即値の代替としての
4.10.5
問題
上のパイプライン・ステージのレイテンシを使用して,問題4.10.3と同様に速度向上の度合いを計算せよ.ただし今度は,クロック・サイクル時間の変更(の可能性)を考慮に入れること.分岐の判定がEXステージからIDステージに繰り上げられると,IDステージのレイテンシは50%増大し,EXステージは10ps短縮されるとする.
比較は、4.10.3で登場した「分岐先がEXステージで判明するパイプライン」から「分岐先がIDステージで判明するパイプライン」への変更として行う。ただし変更後はクロックサイクル時間が伸びる可能性がある。
解答
1.11
解説
- 変更後、IDステージのレイテンシは180ps、EXステージは140psになる。律速ステージはIFであり、クロックサイクル時間は200ps。したがってクロックサイクル時間は変更前と変わらない。
- 速度向上は4.10.3の検討と全く同様に1.11。
4.10.6
問題
分岐の際にはパイプラインにストールを挿入し,遅延スロットはないものとする.beq命令のアドレス計算がEXステージからMEMステージに移されたならば,新しいクロック・サイクル時間および上の命令列の実行時間はどうなるか.この変更により,どれだけ速度が向上するか.ただし,EXステージのレイテンシは20ps短縮され,MEMステージのレイテンシは変わらないとする.
比較は、「分岐先がEXステージで判明するパイプライン」から、「分岐先がMEMステージで判明するパイプライン」への変更として行う。ただし変更後はクロックサイクル時間が短くなる可能性がある。両者ともに、EX/MEMステージの統合は行わないものとする。
解答
新しいクロックサイクル時間は不変で200ps。
速度向上は0.916。
解説
比較すべき両者のパイプライン図を描く。
分岐先がEXステージで判明するパイプライン:

分岐先がMEMステージで判明するパイプライン:

前者は11クロック、後者は12クロック。
クロックサイクル時間については、どちらもIFステージが律速なので変わらない。
速度向上は \(\frac{11}{12} = 0.916\) 。
4.11
下記のループを検討する.
1 | loop: lw r1,0(r1) |
分岐は完全に予測され(制御ハザードに起因するパイプライン・ストールは発生しない),遅延スロットは存在せず,フォワーディングが全面的に採用されているとする.また,何回もループを繰り返した後に,このループが終了するものとする.
本では land という命令が使われていたが、 and の誤植と判断した。
4.11.1
問題
このループの3巡目の最初の命令をフェッチするサイクルから,4巡目の最初の命令をフェッチできるようになるサイクルの直前までの実行の様子を,パイプライン図で示せ.(3巡目だけではなく)すべての過程でパイプラインに流れ込む,すべての命令を示せ.
解答

解説
まずは、3巡目の開始から4巡目の開始までのパイプライン図を描く。データハザードを考慮し、必要なストールを挟んだ図を描く。

4巡目先頭の lw を除いた12クロックに関係する前後の命令も含めて記載したのが解答の図。
4.11.2
問題
5つのパイプライン・ステージで実質的な処理が行われているサイクルの数は,全サイクルのどのくらいの割合か.
解答
86.8%
解説
4.11.1で描いた絵について、
- 全ステージ数: 38
- 実質的な処理が行われていないステージ(塗りつぶしのないステージ)数: 5
なので、 \(100 \times \frac{38 - 5}{38} = 86.8%\)
4.12
この問題は,パイプライン方式のプロセッサにおけるフォワーディングのコスト/複雑性/性能のトレードオフに関して,読者の理解を助けることを意図している.この演習問題では,図4.45のパイプライン方式のデータパスを取り上げる.次の問題では,プロセッサ内で実行されるすべての命令には,いずれかのタイプのRAWデータ依存関係(データ書き込み後の読み出し)がある,と想定している.タイプの内訳は下の表に示すとおりである.RAWデータ依存関係のタイプは,該当のデータを書き込むステージ(EXまたはMEM)と,それを使用する命令がいくつ後であるかによって示される.1stはデータを書き込んだ命令の1つ後の命令がそのデータを使用することを,2ndはデータを書き込んだ命令の2つ後の命令がそのデータを使用することを,それぞれ意味する.レジスタへの書き込みはクロック・サイクルの前半で行われ,レジスタからの読み出しはクロック・サイクルの後半で行われるものとする.したがって,「EXto\(3^{rd}\)」および「MEMto\(3^{rd}\)」は依存関係がない.データ・ハザードを招かないからである.また,データ・ハザードがない場合のプロセッサのCPIは1であるとする.
| EX to 1st のみ | MEM to 1st のみ | EX to 2nd のみ | MEM to 2nd のみ | EX to 1st および MEM to 2nd | その他のRAW依存関係 |
|---|---|---|---|---|---|
| 5% | 20% | 5% | 10% | 10% | 10% |
個々のパイプライン・ステージのレイテンシを下の表に示すように想定する.EXステージに関しては,フォワーディング(FW)を行わない場合と,フォワーディングを行う場合のタイプごとに,レイテンシを別々に示してある.
| IF | ID | EX (FWなし) | EX (全面的にFW) | EX (EX/MEMからのみFW) | EX (MEM/WBからのみFB) | MEM | WB |
|---|---|---|---|---|---|---|---|
| 150ps | 100ps | 120ps | 150ps | 140ps | 130ps | 120ps | 100ps |
4.12.1
問題
フォワーディングを行わない場合,発生するデータ・ハザードに対して,どのくらいの割合でパイプライン・ストールを挿入する必要があるか.
解答
85%
解説
フォワーディングなしでストールを挟まなければ、下図のようなデータハザードが起こる。

必要なストール数は以下。
- EX to 1stのみ: 2
- EX to 2ndのみ: 1
- MEM to 1stのみ: 2
- MEM to 2ndのみ: 1
- EX to 1st および MEM to 2nd: 2
各種命令の頻度と合わせ、必要なストールの割合は、
\[
5\% \times 2 + 5\% \times 1 + 20\% \times 2 + 10\% \times 1 + 10\% \times 2 = 85\%
\]
4.12.2
問題
フォワーディングを行う場合(フォワーディング可能な結果をすべてフォワーディングする),発生するデータ・ハザードに対して,どのくらいの割合でパイプライン・ストールを挿入する必要があるか.
解答
20%
解説
フォワーディングありでストールを挟まなければ、下図のようなデータハザードが起こる。

必要なストール数は以下。
- EX to 1stのみ: 0
- EX to 2ndのみ: 0
- MEM to 1stのみ: 1
- MEM to 2ndのみ: 0
- EX to 1st および MEM to 2nd: 0
各種命令の頻度と合わせ、必要なストールの割合は、
\[
20\% \times 1 = 20\%
\]
4.12.3
問題
全面的なフォワーディングを行うために必要な,3入力マルチプレクサのコストを負担する余裕がないものとする.EX/MEMパイプライン・レジスタからのフォワーディング(次サイクルへのフォワーディング)だけに留めるか,MEM/WBパイプライン・レジスタからのフォワーディング(2サイクルのフォワーディング)だけに留めるかを,決定しなければならない.どちらの方が,パイプラインをストールさせるサイクル数が少なくて済むか.
解答
MEM/WBパイプラインレジスタからのフォワーディングにとどめた場合。
解説
EX/MEMパイプラインレジスタからのフォワーディングだけある場合は、下図のようなデータハザードが起こる。

必要なストール数は以下。
- EX to 1stのみ: 0
- EX to 2ndのみ: 1
- MEM to 1stのみ: 2
- MEM to 2ndのみ: 1
- EX to 1st および MEM to 2nd: 2
“EX to 1st および MEM to 2nd” においては、1クロック分のストールだけでは足りない(EXの結果を2ステージ分先のEXの入力に渡す手段がないので)点に注意。
各種命令の頻度と合わせ、必要なストールの割合は、
\[
5\% \times 1 + 20\% \times 2 + 10\% \times 1 + 10\% \times 2 = 75\%
\]
MEM/WBパイプラインレジスタからのフォワーディングだけある場合は、下図のようなデータハザードが起こる。

必要なストール数は以下。
- EX to 1stのみ: 2
- EX to 2ndのみ: 0
- MEM to 1stのみ: 1
- MEM to 2ndのみ: 0
- EX to 1st および MEM to 2nd: 2
各種命令の頻度と合わせ、必要なストールの割合は、
\[
5\% \times 2 + 20\% \times 1 + 10\% \times 2 = 50\%
\]
後者のほうがパイプラインをストールさせるサイクル数が少なくて済む。
4.12.4
問題
与えられたハザードの確率とパイプライン・ステージのレイテンシのもとで,フォワーディング機能のないパイプラインに全面的なフォワーディング機能を付加したならば,速度はどれだけ向上するか.
解答
1.54倍
解説
4.12.1と4.12.2の比較になる。
- フォワーディング機能のないパイプライン:
- CPI: 1.85
- クロックサイクル時間: 150ps (IFステージが律速)
- 全面的なフォワーディング機能があるパイプライン:
- CPI: 1.20
- クロックサイクル時間: 150ps (IF, EXステージが律速)
速度向上は \(\frac{1.85 \times 150\rm{ps}}{1.20 \times 150 \rm{ps}} = 1.54\)
4.12.5
問題
時間旅行のパラドックスめいたフォワーディングを追加してデータ・ハザードをすべて回避できるならば,さらにどれだけ速度が向上するか(通常のフォワーディング機能を備えたプロセッサと比べて).新たに開発すべき時間旅行用の回路により,全面的なフォワーディングを行うEXステージで,レイテンシが100ps増えるものとする.
解答
0.72倍
解説
「時間旅行のパラドックスめいたフォワーディング」があるというのは、要するにデータハザードが全く発生しないということ。この場合のCPIは1。クロックサイクル時間は250ps (EXステージが律速)。
通常のフォワーディング機構を備えたプロセッサの場合は、4.12.2のものと同じく、CPIは1.20。クロックサイクル時間は150ps (IF, EXステージが律速)。
速度向上は \(\frac{1.20 \times 150\rm{ps}}{1 \times 250\rm{ps}} = 0.72\)
EXステージのレイテンシの向上による速度低下が支配的になってしまった。
4.12.6
問題
問題4.12.3と同じ問いに答えよ.ただし今度は,2つの選択肢のうちのどちらの方が命令当たりの時間が短くなるか判定せよ.
解答
EX/MEMパイプラインレジスタからのフォワーディングだけある場合。
解説
- EX/MEMパイプラインレジスタからのフォワーディングだけある場合:
- CPI: 1.75 [clock/命令]
- クロックサイクル時間: 150 [ps/clock] (IFステージが律速)
- 命令当たりの時間: \(1.75 \rm{[clock/命令]} \times 150 \rm{[ps/clock]} = 262.5 \rm{[ps/命令]}\)
- EX/MEMパイプラインレジスタからのフォワーディングだけある場合:
- CPI: 1.50 [clock/命令]
- クロックサイクル時間: 150 [ps/clock] (IFステージが律速)
- 命令当たりの時間: \(1.50 \rm{[clock/命令]} \times 150 \rm{[ps/clock]} = 225.0 \rm{[ps/命令]}\)
後者のほうが命令当たりの時間が短い。
4.13
この問題は,フォワーディング,ハザード検出,そして命令セット・アーキテクチャの設計の関係について,読者の理解を助けることを意図している.この演習問題では,下の表に示す命令列を取り上げる.これらは5ステージのパイプライン方式のデータパス上で実行されるものとする.
1 | add r5,r2,r1 |
4.13.1
問題
ハザード検出もフォワーディングも行われない場合に,命令が正しく実行されることを保証するために,この命令列にnopを挿入せよ.
解答
1 | add r5,r2,r1 |
解説
データハザードを気にせずパイプライン図を描く。

データハザードを回避させるため、2番目の命令を2ステージ分ストールさせ、4晩名の命令を1ステージ分ストールさせる。

ストールを実現するためのnop命令を挟んだ命令列が解答のもの。
4.13.2
問題
問題4.13.1と同じ問いに答えよ.ただし今度は,命令の変更や並べ替えをしても,ハザードを回避できない場合にのみ,nopを使用する.修正したコード内で一時的に値を保持するために,レジスタr7を使用してよい.
解答
1 | add r5,r2,r1 |
解説
r5 とRAW依存を持たない命令を、 r5 へ書き戻しを行う命令の直後に実行すると、 r5 に関するデータハザードをなくすことができる。今回は lw r2,0(r2) がそれに該当する。

今度は、 r3 のRAW依存のせいで2ステージ分のストールが必要になっている。 r3 に依存しない sw を前倒す。

nop 2つでデータハザードを回避できた。
4.13.3
問題
プロセッサにフォワーディング機能を持たせたが,ハザード検出ユニットを実装し忘れたとする.上のコードを実行したときに,何が起こるか.
解答
意味論通りに実行される。
解説

この命令列ではフォワーディングさえあればハザードは起こらないので、意味論通りに実行される。
4.13.4
問題
フォワーディング機能がある場合,上のコードを実行した最初の5サイクルにおいて,図4.60のハザード検出ユニットおよびフォワーディング・ユニットにより,各サイクルでどの信号がアサートされるか.
解答
| サイクル | PCWrite | IF/IDWrite | ForwardA | ForwardB |
|---|---|---|---|---|
| cc1 | 1 | 1 | 00 | 00 |
| cc2 | 1 | 1 | 00 | 00 |
| cc3 | 1 | 1 | 00 | 00 |
| cc4 | 1 | 1 | 10 | 00 |
| cc5 | 1 | 1 | 00 | 00 |
解説
4.13.3で見たように、ハザードは起こらないので、どのサイクルでも PCWrite と IF/IDWrite は 1 となる。
フォワーディングが起こるのは、cc4における ForwardA のみ。サイクル4では、直前のEXステージからの出力を受け取るので、 ForwardA は 10 となる。
4.13.5
問題
フォワーディング機能がない場合,図4.60のハザード検出ユニットに関して,新たにどんな入力信号および出力信号が必要になるか.
解答
- 新たな入力信号:
- EX/MEM.MemRead
- ID/EX.MemtoReg
- EX/MEM.RegisterRt
- ID/EX.RegisterRt
- EX/MEM.RegisterRd
- 新たな出力信号: なし
解説
フォワーディング機能があれば、データハザードは「ロード命令のRtを直後の命令の入力として使う」場合だけである。データハザードの検出ロジックは、本文に記載がある通り、
1 | ID/EX.MemRead and |
と定式化できる。このロジックは、「直後の命令」のIDステージで発火する。
フォワーディング機能がない場合は必ずWBまで待つ必要があるので、以下のデータハザードが発生し得る。
- ロード命令:
- この命令のRtを、1つ後の命令が入力として使う
- この命令のRtを、2つ後の命令が入力として使う
- ALU命令:
- この命令のRdを、1つ後の命令が入力として使う
- この命令のRdを、2つ後の命令が入力として使う
それぞれの検出ロジックは以下のように記述できる。
1 | // データハザード1 (「1つ後の命令」のIDステージで発火) |
ここで使われている項のうち、図4.60のハザード検出ユニットの入力に足りないのは、
- EX/MEM.MemRead
- ID/EX.MemtoReg
- EX/MEM.RegisterRt
- ID/EX.RegisterRt
- EX/MEM.RegisterRd
データハザード1~4のいずれも、IDステージでの検出時点で、その命令をnopに変更すれば良い。それは図4.59で見たように、ID/EXのパイプラインレジスタのEX, MEM, WBの各制御フィールドををすべて0にすれば良い。
4.13.6
問題
問題4.13.5で変更した新しいハザード検出ユニットを使用して,上のコードを実行した場合,最初の5サイクルの各サイクルでアサートされる出力信号を示せ.
4.13.5と同じく、フォワーディング機構はないものとする。
解答
| サイクル | PCWrite | IF/IDWrite |
|---|---|---|
| cc1 | 1 | 1 |
| cc2 | 1 | 1 |
| cc3 | 0 | 0 |
| cc4 | 0 | 0 |
| cc5 | 1 | 1 |
解説
ハザード検出ユニットの働きにより、 lw r3,4(r5) が2度 nop に書き換わる。

4.14
この問題は,パイプライン方式のプロセッサにおける遅延スロット,制御ハザード,そして分岐の関係について,読者の理解を助けることを意図している.この演習問題では,下に示すMIPSのコードを取り上げる.5ステージのパイプライン方式をとり,全面的なフォワーディング機能および分岐成立予測機能を備えたプロセッサ上で,これらのコードが実行されるものとする.
1 | lw r2,0(r1) |
4.14.1
問題
このコードの実行の様子を示すパイプライン図を描け.ただし,遅延スロットはなく,分岐はEXステージで行われるものとする.
解答

解説
図中の命令の文字列の下部に、起こったイベントをコメント形式で記載したので、参照のこと。
4.14.2
問題
問題4.14.1と同じ問いに答えよ.ただし今度は,遅延スロットを使用するものとする.上のコードにおいて,分岐命令直後の命令は,その分岐命令の遅延スロット中の命令となる.
解答

解説
beq の先行命令は、 beq のオペランドのレジスタの値を出力するものなので、図4.64の(a)の形式の分岐スロットのスケジューリングはできない。
したがって(b)または(c)のスケジューリングをする必要があるが、問題文での指示により、(c)の形式を採る。
(c)の形式に置いて、分岐スロットに入れることのできる命令は、「分岐が成立した場合でも、分岐スロット内の命令実行がプログラムの意味論を破壊しない」命令に限る。
この問題で分岐スロットに入り得るのは lw r3,0(r2) と add r1,r3,r1 。いずれも、分岐が成立した場合に使用され得るレジスタ (r2, r1) を書き換える命令なので、これらは分岐スロットに入れてはならない。
この前提で考えると、分岐命令EXステージが完了してから、確定した分岐先の命令のIFステージを開始できる。
これにより、解答のパイプライン図を得る。
4.14.3
問題
分岐の確定を1ステージ早める1つの方法は,条件分岐におけるALUでの演算をなくすことである.たとえば,bez rd,Labelやbnez rd,Labelといった命令が考えられる.これらの命令はそれぞれ,レジスタの値が0のとき,または0でないときに分岐することになる.beq命令の代わりにこうした分岐命令を使用するように,上のコードを変更せよ.一時レジスタとして,レジスタr8を使用できるものとする.また,R形式命令のseq(等しい場合に設定)を使用できるものとする.
4.8節で,分岐の実行をIDステージに繰り上げることにより,制御ハザードの問題を緩和できることを説明した.そうするためには,図4.62に示したように,IDステージに専用の比較器を備える必要がある.しかしこのやり方を採用すると,IDステージのレイテンシが増大する可能性が生じ,追加のフォワーディング・ロジックとハザード検出回路も必要になる.
解答

解説
beq 命令を使うとALUでの演算が発生する設定なので、 beq 命令を bez, bnez で置き換えることを考える。
1 | beq r2,r0,label2 |
は、
1 | seq r8,r2,r0 # r8 <- r2 == r0 |
と置き換えられる。したがって、命令列全体は以下のようになる。
1 | lw r2,0(r1) |
大問の設定に従い、 bnez では分岐成立予測(すなわち、指定されたラベルへ常にジャンプと予測)が行われるとする。
この設定で、解答のパイプライン図を得る。
4.14.4 (未回答)
問題
上のコード中の最初の分岐命令を例として使用し,図4.62に示したようなIDステージでの分岐の実行をサポートするのに必要となる,ハザード検出ロジックを説明せよ.その新しいロジックでは,どのタイプのハザードを検出できるか.
解答
解説
4.14.5 (未回答)
問題
上のコードに関して,分岐の実行をIDステージに繰り上げることにより,速度がどれだけ向上するか.答えの根拠も説明せよ.速度向上の計算においては,IDステージにおける追加の比較はクロック・サイクル時間に影響しないものとする.
解答
解説
4.14.6 (未回答)
問題
上のコード中の最初の分岐命令を例として使用し,IDステージでの分岐の実行をサポートするために追加する必要がある,フォワーディング機能を説明せよ.この新しいフォワーディング・ユニットの複雑性を,図4.62中の既存のフォワーディング・ユニットの複雑性と比較せよ.